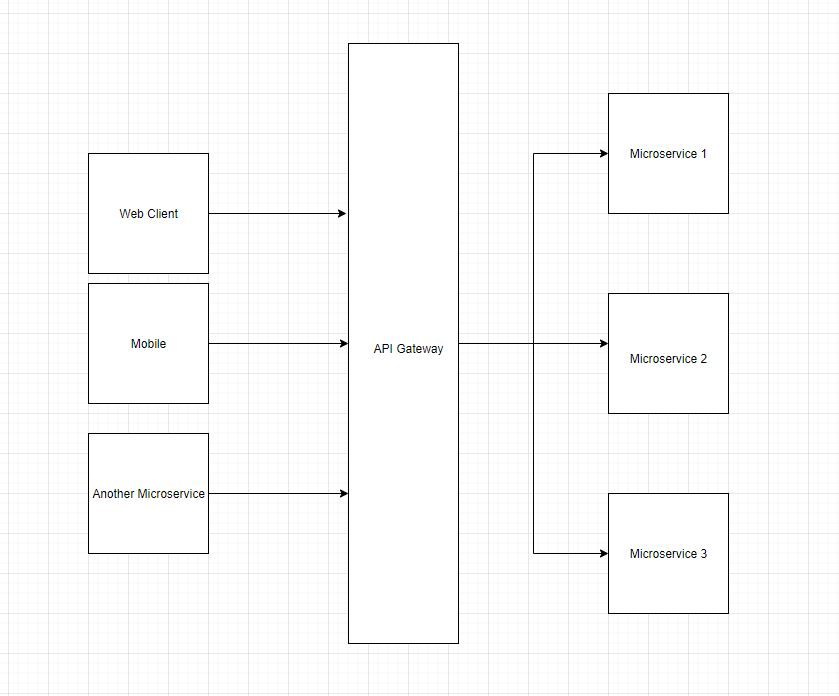
In this post, I will show how we can add integration testing to a Spring Boot application.
Integration tests play a key role in ensuring the quality of the application. With a framework like Spring Boot, it is even easier to integrate such tests. Nevertheless, it is important to test applications with integration tests without deploying them to the application server.
Integration tests can help to test the data access layer of your application. Integration tests also help to test multiple units. For the Spring Boot application, we need to run an application in ApplicationContext to be able to run tests. Integration tests can help in testing exception handling.
Spring Boot Application
For this demo, we will build a simple Spring Boot application with REST APIs. We will be using the H2 In-Memory database for storing the data. Eventually, I will show how to write an integration test. This application reads a JSON file of vulnerabilities from the National Vulnerability Database and stores it in the H2 database. REST APIs allow a user to fetch that data in a more readable format.
Dependencies
First, we want to build integration tests in this application, so we will need to include the dependency spring-boot-starter-test .
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'junit:junit:4.13.1'
runtimeOnly 'com.h2database:h2:1.4.200'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
This dependency of spring-boot-starter-test allow us to add testing-related annotations that we will see soon.
REST API
Now as I said previously, we will have a REST API to fetch national vulnerability database data. We will create a REST controller with two APIs one to fetch a list of vulnerabilities and one to fetch a vulnerability by CVE id.
@RestController
@RequestMapping("/v1/beacon23/vulnerabilities")
public class CveController
{
@Autowired
private CveService cveService;
@GetMapping("/list")
public List getAllCveItems(@RequestParam(required = false, name="fromDate") String fromDate, @RequestParam(required = false, name=
"toDate") String toDate)
{
List cveDTOList = cveService.getCveItems(fromDate, toDate);
if(cveDTOList == null || cveDTOList.isEmpty())
{
return new ArrayList<>();
}
else
{
return cveDTOList;
}
}
@GetMapping
public ResponseEntity getCveItemById(@RequestParam("cveId") String cveId)
{
CveDTO cveDTO = cveService.getCveItemByCveId(cveId);
if(cveDTO != null)
{
return new ResponseEntity<>(cveDTO, HttpStatus.OK);
}
else
{
return new ResponseEntity<>(HttpStatus.NO_CONTENT);
}
}
}
So we have
- /v1/beacon23/vulnerabilities/list – to fetch a list of vulnerabilities
- /v1/beacon23/vulnerabilities?cveId=value – to fetch vulnerability by CVE id.
Service
Now, most of the business logic and validation happen in Service class. As we saw in our API, we use CVEService to fetch the required data.
@Autowired
public CveDataDao cveDataDao;
public List getCveItems(String from, String to)
{
LOGGER.debug("The date range values are from = {} and to = {}", from, to);
List cveDataList = cveDataDao.findAll();
List cveDTOList = new ArrayList<>();
for(CveData cveData : cveDataList)
{
List cveList = cveData.getCveItems();
for(CveItem cveItem: cveList)
{
Date fromDate;
Date toDate;
if(!isNullOrEmpty(from) && !isNullOrEmpty(to))
{
fromDate = DateUtil.formatDate(from);
toDate = DateUtil.formatDate(to);
Date publishedDate = DateUtil.formatDate(cveItem.getPublishedDate());
if(publishedDate.after(toDate) || publishedDate.before(fromDate))
{
continue;
}
}
CveDTO cveDTO = convertCveItemToCveDTO(cveItem);
cveDTOList.add(cveDTO);
}
}
return cveDTOList;
}
private boolean isNullOrEmpty (String str)
{
return (str == null || str.isEmpty());
}
private String buildDescription (List descriptionDataList)
{
if(descriptionDataList == null || descriptionDataList.isEmpty())
{
return EMPTY_STRING;
}
else
{
return descriptionDataList.get(0).getValue();
}
}
private List buildReferenceUrls (List referenceDataList)
{
return referenceDataList.stream().map(it -> it.getUrl()).collect(Collectors.toList());
}
public CveDTO getCveItemByCveId(String cveId)
{
List cveDataList = cveDataDao.findAll();
CveDTO cveDTO = null;
for(CveData cveData : cveDataList)
{
List cveItems = cveData.getCveItems();
Optional optionalCveItem =
cveItems.stream().filter(ci -> ci.getCve().getCveMetadata().getCveId().equals(cveId)).findAny();
CveItem cveItem = null;
if(optionalCveItem.isPresent())
{
cveItem = optionalCveItem.get();
}
else
{
return cveDTO;
}
cveDTO = convertCveItemToCveDTO(cveItem);
}
return cveDTO;
}
Usage of @SpringBootTest
Spring Boot provides an annotation @SpringBootTest that we can use in integration tests. With this annotation, the tests can start the application context that can contain all the objects we need for the application to run.
Integration tests provide an almost production-like scenario to test our code. The tests annotated with @SpringBootTest create the application context used in our tests through application class annotated with @SpringBootConfiguration.
These tests start an embedded server, create a web environment, and then run @Test methods to do integration testing. We need to add few attributes to make sure we can start web environment while using @SpringBootTest.
- Attribute
webEnvironment– To create a web environment with a default port or a random port.
We can also pass properties to use for tests using an active profile. Usually, we use these profiles for different environments, but we can also use a special profile for tests only. We create application-dev.yml, application-prod.yml profiles. Similarly, we can create application-test.yml and use the annotation @ActiveProfiles('test') in our tests.
Example of Integration Test
For our REST API, we will create an integration test that will test our controller. We will also use TestRestTemplate to fetch data. This integration test will look like below:
package com.betterjavacode.beacon23.tests;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.web.client.TestRestTemplate;
import org.springframework.boot.web.server.LocalServerPort;
import org.springframework.http.HttpEntity;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpMethod;
import org.springframework.http.ResponseEntity;
import org.springframework.test.context.junit4.SpringRunner;
import static org.junit.Assert.assertNotNull;
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class CveControllerTest
{
@LocalServerPort
private int port;
TestRestTemplate testRestTemplate = new TestRestTemplate();
HttpHeaders headers = new HttpHeaders();
@Test
public void testGetAllCveItems()
{
HttpEntity entity = new HttpEntity<>(null, headers);
ResponseEntity responseEntity = testRestTemplate.exchange(createURLWithPort(
"/v1/beacon23/vulnerabilities/list"),HttpMethod.GET, entity, String.class);
assertNotNull(responseEntity);
}
private String createURLWithPort(String uri)
{
return "http://localhost:" + port + uri;
}
}
We use @SpringBootTest annotation for our test class and set up the application context by using webEnvironment with a RANDOM_PORT. We also mock the local web server by setting up a mock port with @LocalServerPort.
TestRestTemplate allows us to simulate a client that will call our API. Once we run this test (either through gradle build OR through IntelliJ), we will see the Spring Boot Application Context setup running and the application running at a random port.
One disadvantage of creating integration tests with @SpringBootTest is that it will slow down building your application. In most enterprise environments, you will have this set up through continuous integration and continuous deployment. In such scenarios, it slows down the process of integration and deployment if you have a lot of integration tests.
Conclusion
Finally, you should use integration testing in the Spring Boot application or not, it depends on your application. But despite the drawback, it is always useful to have integration tests that allow testing multiple units at a time. @SpringBootTest is a handy annotation that can be used to set up an application context, allowing us to run tests close to a production environment.
References
- integration Testing with Spring Boot – Integration Testing