In this post, we will explore how databases work. There are number of databases including SQL and NoSQL, but we will mostly be talking about relational databases.
Introduction
Every time, I have used databases for queries, I have wondered how the databases work internally. Coming from programming languages background, it is easy to understand on the surface.
A user writes a query with certain syntax, the code gets compiled into machine code with grammar and an interpreter executes the machine code. That’s a simple understanding.
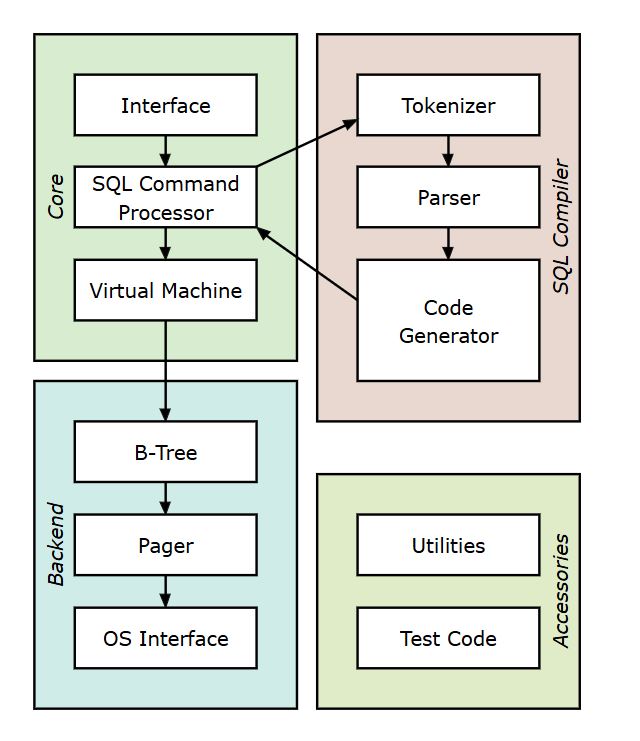

In short, databases have frontend of Interface, SQL Command Processor and Virtual Machine.
And there is a backend of B-Tree, Pager and OS Interface.
This particular architecture is specific to SQLite database, but most of the other SQL (relational) databases work in the similar ways.
Overview of Database
Let’s dive into the overview of the database internals. In previous section, I showed the architecture that contains frontend and backend components. Let’s look at those components and what they do
A user types SQL query using user interface. SQL query goes through three stages tokenizer, parser and code generator.
From the written SQL query, tokenizer creates identifiable tokens. These tokens are then parsed in attribute grammar for the language. Code generator takes the generated grammar to create virtual machine bytecode.
Virtual-machine then takes operations generated from bytecode and stores in a data structure B-Tree. Virtual Machine is a big switch statement.
B-Tree consists of many nodes and each node is a page. B-Tree retrieves a page from disk or saves the page to disk by issuing a command to Pager.
Pager does the majority of work of reading and writing in the database files. OS Interface is an OS dependent layer and helps Pager in reading and writing the data in files. Depending on the OS of server where the database is running, OS interface can function differently.
Understanding B-Tree
Database uses B-Tree data structure to represent table and index.
B-Tree is a data structure that allows efficient data storage and retrieval.
Search for a specific value is O(log n) for time complexity.
Insert OR Delete a value is also O(log n) for time complexity.
Space Complexity while using B-Tree is also O(n).
B-Tree is a self-balancing tree that keeps the data sorted. Having sorted data allows fast search and insertion or deletion operation.
The main difference between Binary Tree and B-Tree is that B-Tree can have more than 2 children.
B-Tree properties
- Every node has at most m children
- Every node except root and leaves has at least m/2 children
- Root node has at least 2 children unless it is a leaf node
- All leaves appear on the same level
- A non-leaf node with k children contains k-1 keys
Binary Search
- Each node contains a sorted array of keys.
- Binary search is used within each node to find key.
- It reduces the number of comparisons needed within nodes.
The way search works in B-Tree is as follows:
- Search starts at the root node.
- Use binary search to find either the key if it exists in current node OR find the correct child node to traverse next
- Repeat the process until key is found or leaf is reached.
Conclusion
In this post, we shared the internals of database and how database works. If you want to read more about SQLite DB, you can visit the official documentation here.