In this post, I want to talk about observability and how to design a system with observability. Observability just means watching and understanding internal state of a system through external outputs. But what exactly are we watching when it comes to systems or microservices? We’ll dig into that. In one of my previous posts, I have talked about observability by collecting metrics.
Often, we build a system backward. We start with an idea and make a product for people to use. We hope everything works smoothly, but it rarely does. There are always problems, challenges, and the product might not work as users expect. Users might say your product isn’t working, get frustrated, and leave. In the end, it just becomes another not-so-great product.
When users report problems, an engineer has to figure out why it happened. Having logs that show what went wrong can be really helpful. But in these situations, we’re reacting—the system is already doing something, and we’re waiting for it to mess up. If someone else has to understand our system without knowing all the technical stuff, it’s tough for them to figure out what’s happening. They might have to use the product to really get what’s going on. Is there a better way? Can we design our system so anyone can understand how it’s doing without diving into all the complicated details?
How do we design a system that can allow us to observe it? Can we have a mechanism to alert an issue before a customer comes to us? How can observability help us here?
2. Components of Observability
There are 4 components to Observability:
Log Aggregation
Metrics Collection
Distributed Tracing
Alerting
Each of these 4 components of observability is a building block for reliable system design.
Anyhow, let’s look at them.
2.1 Log Aggregation
Whether you are using Microservices or Monoliths for your system, there is some communication between frontend and backend OR backend to backend. The data flows from one system to other following some business logic. Logs are the key to help us understand how the production system is working.
While designing any system, we should form a convention on how we want to log the information. Logging right data should be a prerequisite to building any application. Every system design comes with its own set of challenges, log aggregation for the system is the least of the challenge. Having log aggregation will help in long term. How you implement log aggregation can depend on variety of factors like the tech stack, cloud provider. With modern tools, it has become easy to query aggregated logs.
When you start building your system, adopt a convention on how and what to log from your application. One caution to take into account is to not log any personal identifying information.
2.2 Metrics Collection
Whenever your system will start to mature, you will notice the trends of resources it has been using. You might face issues where you might have allocated less space or memory. Then on emergency basic, you will need to increase memory or space. Even in that scenario, you might have to make a judgement call by how much to increase.
This is where metrics collection comes into picture. If we build a system that can provides us metrics like latency, Memory/CPU usage, disk usage, read/write ops, it can help us for capacity planning. Also, it will provide more accurate information on how we want to scale if we start to see heavy load.
Metrics can also allow us to detect anomalies in our system. With monitoring tools available, it has become easier to collect metrics. Datadog, Splunk, New Relic are few of the observability tools.
Other than system metrics, one can also build product metrics using such tools for metrics collection. Product metrics can allow to see how your users have been using or not using your application, what does your product lack? It is one of the ways to gather feedback of your own product and improve on it.
2.3 Distributed Tracing
Overall, the microservices for various systems are getting complex. All microservices within a single system talk to each other and process some data. It would be nice if there was a way to trace each call that comes from the client to these services. That’s where distributed tracing comes into picture.
Distributed tracing is capturing activity within a local thread using span. Eventually, collecting all these spans at one central place. All these spans are linked to each other through a common correlation id OR trace id.
The advantage of distributed tracing is to be able to see any issue or anomaly of the microservice. This allows us to trace an end-to-end call.
2.4 Alerting
At the beginning of this post, I mentioned how users of our product can get frustrated and bring to our attention various issues. In many such cases, we are reactive. Once the user reports an issue, we investigate why it happened and how it can not happen again.
With distributed tracing and metrics, can we create alerts to inform us about any issues in our application? Yes, that’s where the alerting comes into picture. We can also collect metrics related to errors OR gather errors data through distributed tracing and logs.
We also want to be careful where we don’t want to alert too much that it becomes a noise. Having some threshold around errors helps. Anomaly alerts can be handy. At the end, it all depends on your application and all the observability data that you will gather.
3. System Design with Observability
We talked about the key components around observability. We are aware of designing a system with certain requirements and industry practices. How do we build this system with observability in mind? Setting certain service level agreements (SLA) and service level objectives (SLO) before building your application can direct engineers. Engineers can then build observability as they build the application instead of coming at it later. This will be more proactive approach. In many microservices, we can also integrate with opentelemetry. Opentelemetry is a vendor neutral observability framework.
4. Conclusion
In this post, I discussed monitoring, observability and how an engineer can think about these while building a system. To be more proactive with these practices, system design should take observability into account.
In this post, we will discuss a new design pattern – the worker pattern and how to use this pattern in microservices. Previously, I have covered communication and event-driven patterns in microservices.
What is a Worker Pattern?
Let’s start with a scenario. You have a microservice that processes business logic. For a new set of business requirements, you need to build a new feature in microservice. This feature will be resource-intensive for processing a large set of data. One way to handle any resource-intensive processing of data is to do that processing asynchronously. There are different ways you can implement this for asynchronous handling. You can create a job and queue it in a queue system. OR you can publish an event for another service to process the data. Irrespective of your approach, you will need a way to control the flow of this data.
With either approach, you want to avoid your main service getting blocked for processing these asynchronous events. Let’s assume for a second if you went with a job approach, you can use Bull Queue (redis-based queuing mechanism).
Bull Queue offers a processor for each job that your service will add to the queue. Nevertheless, this processor runs in its own process and can perform the job. For resource-intensive operations, this can still have a bottleneck and can probably stop performing the way you wanted.
In such cases, you can create a standalone worker. This standalone worker will run on its own set of resources (like Kubernetes pod). This worker will process the same job that your service added to the queue.
When to use Worker Pattern?
Every use case is different. But the simple heuristic you can use to check how much CPU-heavy work the processor plans to do. If the job from the queue is CPU-heavy, then create a separate processor or worker. In the same service, you can write a separate processor that will execute the job in a separate process. It is also known as Sandbox Processor.
Worker will spin up the standalone service in its own resources and execute the processor. It will not interfere with other processes from the service since it is executing one job. Another advantage of worker patterns is to be able to scale the resources horizontally. If you use a sandbox processor, you might have to scale the services, and all scaled-up resources are equally divided into processes.
Example of Worker Pattern
Let’s look at a quick example of a worker pattern.
We have a simple endpoint that will add a job to a queue. This endpoint is part of a controller in a microservice. This will look like something like below:
To create a standalone worker, we can create a separate module and use that module to create a new application context. For example, we create a new module subscriber.module.ts and it has our consumer (worker/processor) as a provider.
@Processor('worker-pattern-queue')
export class FileQueueProcessor {
}
In a Test-Driven Development, everything starts with writing the tests first. In this post, I discuss handling flakiness in automated tests. If you start your development by writing the tests first, it can help with setting up some assumptions. The challenge with this is that you are not always aware of edge cases. As the saying goes – you don’t know what you don’t know.
What is a flaky test?
To start with, we need to understand the basic definition of a flaky test. Nobody intentionally writes a flaky test. A flaky test is an automated test that gives different results at different executions even when there are no changes in the underlying code. The non-deterministic nature of such tests makes it harder to debug them.
Let’s look at the possible reasons why tests can become flaky.
Reasons for a flaky test
With CI/CD, automated tests have become part of the development process. It goes without saying that automated tests do increase confidence in the process and the product you are trying to build. As we discussed in the previous section, sometimes a test can become flaky even if there is no code change. What are the possible reasons for a flaky test?
Bad Tests – If a developer does not invest enough time to understand the functionality they are trying to test, they can end up writing bad tests. Sometimes with bad data or with wrong logic. Bad tests do represent not enough understanding of the underlying system.
Wrong assumptions – One of the major reasons for a flaky test is the wrong assumptions. When writing a test, the developer does not have all the information and they write the assumptions for a test with the requirements they have in hand, this can result in either wrong or incomplete assumptions. One of the easiest ways to figure out the flaky test is to challenge the assumptions for that test. I have also realized that time can be a dynamic concept and the human mind can not completely conceive the time and it does make it harder to write tests that can involve time elements. Surprisingly, the flaky tests either have time-bound or data-constraint issues.
Concurrency – Whether the concurrency is part of CI/CD execution or user-added for executing tests, it can cause flakiness for automated tests.
How to debug the flakiness of automated tests?
Before you can debug a flaky test, you should check all the following notes to see if anything might be causing the flakiness of the test
memory leak – Memory leaks can cause performance degradation, but can also cause tests to flake more often. You should check if your tests and test environment are functioning optimally.
wait time – Check wait times between tests and for each test. Possibly even increase the wait time allowing each test to complete all the possible requests.
challenge assumptions – The easiest way to debug a flaky test is to look at all the assumptions, and data and challenge them. If you challenge the assumptions and change them, you might find different results.
Remember flakiness of the test is most of the time because of assumptions made about data or the functionality.
Conclusion
In this post, we discussed the flakiness of tests in automated tests and how to debug such tests. Check the framework you are using or the assumptions you are making about the tests.
In this post, I will show how to use a custom protocol mapper with Keycloak. In my previous post, I showed how to use keycloak as an identity-broker. This post focuses on how to use Keycloak for retrieving custom attributes during authentication.
Keycloak offers basic attributes like sub, iss in the access token or id token it generates. If we need some organization-specific or user-specific attributes, we can configure a custom protocol mapper in Keycloak.
Our client application will receive a token that will have attributes from our custom mapper.
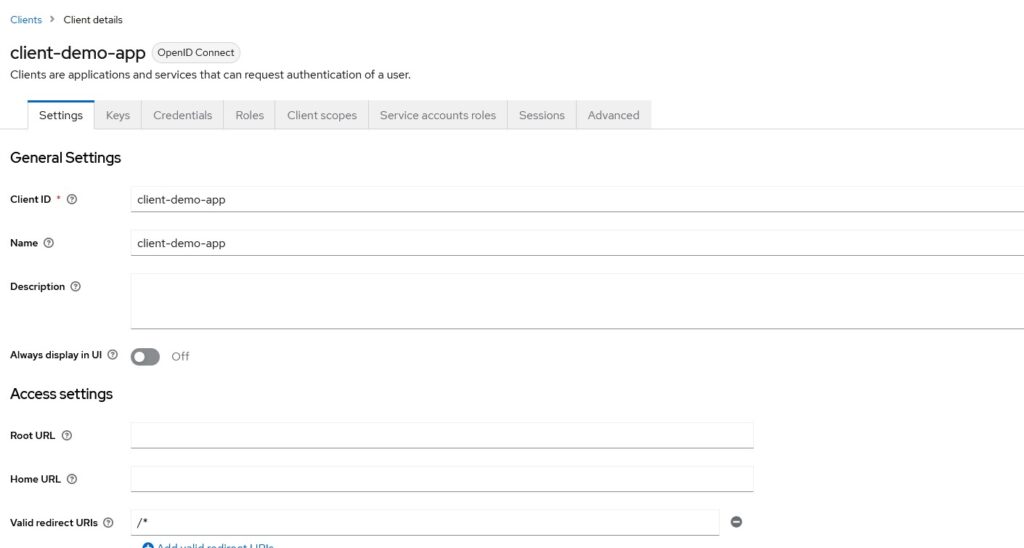
Configure Keycloak for Client
Let’s configure a client in Keycloak for OIDC Protocol.
I have left Root URL, Home URL and Valid Redirect URIs almost empty. When you will have an actual application, you will need to provide a valid redirect URI that Keycloak will redirect to. Your application should handle the response from Keycloak on that URL.
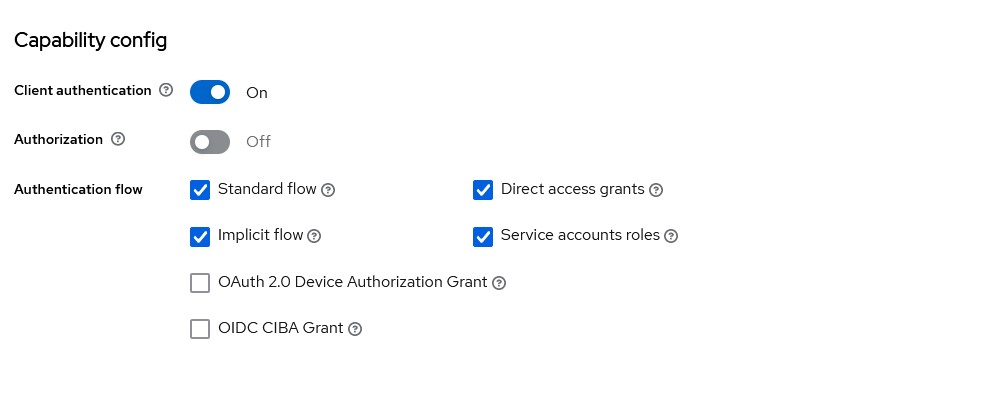
You can configure what flows you will be supporting for OAuth
We leave the rest of the configuration as is for now and revisit when we have out custom mapper ready.
Default Protocol Mapper
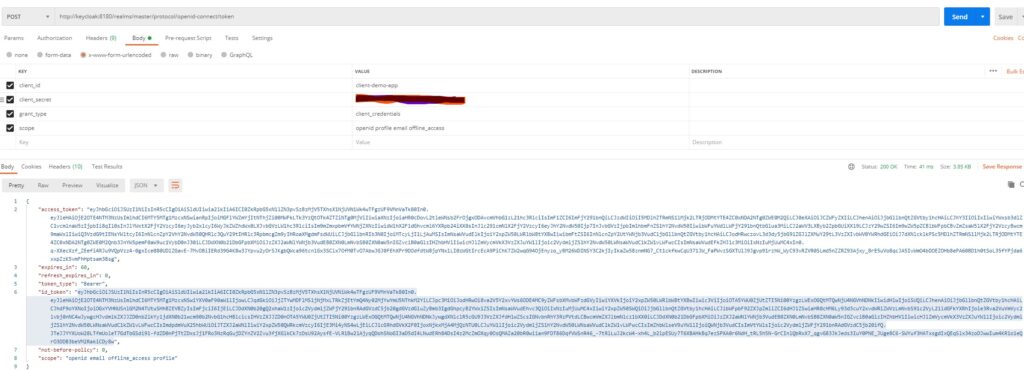
If you run the Keycloak and use the client app that we created previously, we should be able to get Access Token and Id Token. That will provide us with default attributes in the token like below:
As you see in this token, most claims are standard claims that Keycloak provides. For our user, we have not configured email or any other profile attributes, otherwise, Keycloak will provide that too.
Implementing Custom Protocol Mapper
The major advantage of Keycloak is that it allows developers to write different types of extensions. One such extension is Protocol Mapper.
Dependencies
Let’s create a Maven project and add the following dependencies.
In our Maven project, we will create a new class CustomOIDCProtocolMapper. This class will implement few interfaces OIDCAccessTokenMapper, OIDCIdTokenMapper and UserInfoTokenMapper. This class will also extend an abstract class AbstractOIDCProtocolMapper.
In the above code, there are a couple of important methods to look at
setClaims – it adds custom data to token. SimpleTextAttributeValue will be part of the token once we set up that claim.
transformAccessToken and transformIdToken – We can also add additional user attributes to the default Access Token and Id Token. In many cases, you don’t want to expose a lot of user data in Access Token.
Other methods like getDisplayType and getHelpText are helper methods for Keycloak admin console.
Building a jar for Protocol Mapper
Before we can use this custom protocol mapper in our Keycloak configuration, we will need to build our maven project. To be able to use this mapper, we need to add a file with the name org.keycloak.protocol.ProtocolMapper in resources/META-INF/services directory.
Add the following value to this file –
com.betterjavacode.CustomOIDCProtocolMapper
This is our class for custom mapper. Our Keycloak configuration then will be able to identify the jar file that we will add.
Run the command mvn clean install in Maven project. This should build a jar file in the target directory.
Configuring the client with Custom Protocol Mapper
Once the jar file is ready, copy that jar file into the Keycloak configuration. In our case, I am running a Keycloak through a docker container. The docker-compose file Keycloak looks like below:
Make sure you have providers directory in your root directory where this docker-compose.yml file is.
Copy the Custom protocol mapper jar file in providers directory.
Start the docker container with docker-compose -f docker-compose.yml up command.
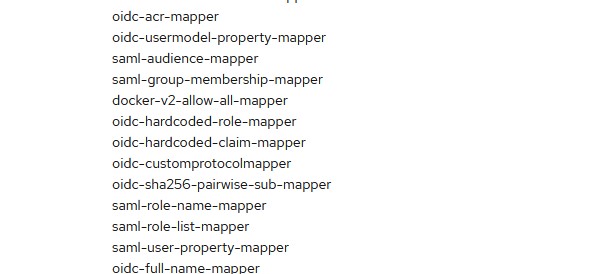
Now let’s configure our client in Keycloak with custom protocol mapper. Once you login to Keycloak admin console, you should be able to see oidc-customprotocolmapper in provider info.
Now, go to the client and client-scopes tab.
Select client-demo-app-dedicated client scope.
On the Mappers tab, select Add Mapper - By Configuration
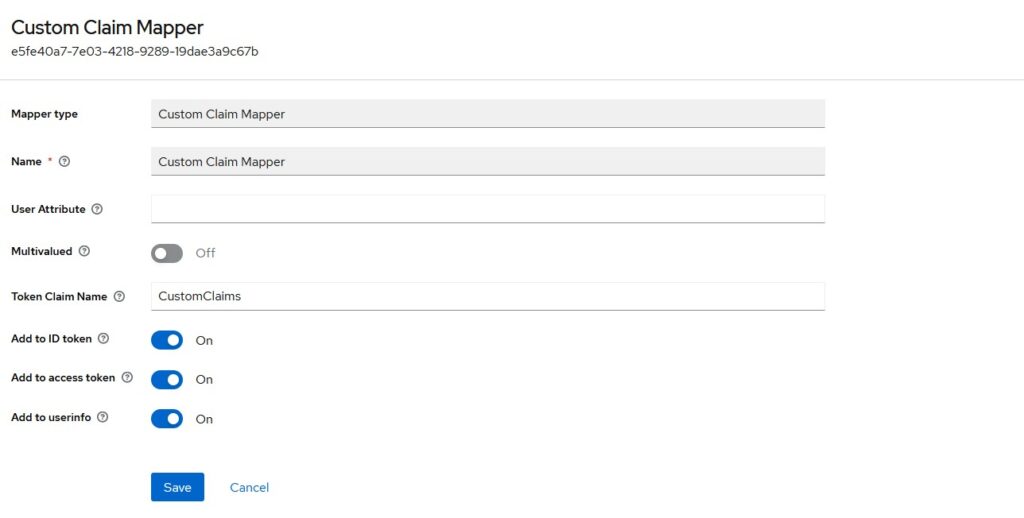
Choose Custom Claim Mapper and it will add to your mapper.
You can choose if you want to include this claim in Access Token or Id Token or Both. Click on Save and it will be added to our list of claims. Now, we are ready to test this mapper.
Demo for Custom Attributes
To test this claim mapper, I will use a postman to call the token endpoint of Keycloak configuration. You will see the access token and id token in response.
Now if we decode that id token, it will show our custom claim as below:
You can see the new claim CustomClaims with the attribute value that we had determined in our code.
Conclusion
In this post, we showed how to configure a custom protocol mapper with Keycloak. Keycloak is an open-source IAM tool and it provides capabilities to configure providers and themes.
Service Provider Application (We are using a spring boot application)
Identity Provider
What is Identity Broker?
An identity broker is a service that integrates two other services. An identity broker usually acts as an intermediary between a service provider and another identity provider. The identity broker creates a relationship with a third-party identity provider to use the provider’s identities to access the service provider application.
In this post, we will show how you can configure Keycloak as an identity broker between a spring boot application and an identity provider.
Start Keycloak with Postgres Database
If you download and run Keycloak as a standalone service, it will H2 (In-Memory) database. But we plan to use the Postgres database. This will also give a lot of clarity on how to use Keycloak with a relational database in an actual production environment.
Create a database called keycloak in Postgres once you set up the database server locally.
To make Keycloak to use the Postgres database, we will need to update some configuration in the Keycloak installation directory. For this demo, I am using Keycloak version 11.0.1. If you are using the latest version, I will share the information below on how to integrate that with the Postgres database.
Go to Keycloak_installation/standalone/configuration directory
OR if you are using the latest version of Keycloak, you can use
kc.bat start-dev
Both of these commands are from a Windows environment perspective. Once the Keycloak server starts, access the Keycloak administration UI in the browser http://localhost:8180
Configure Keycloak with a realm
Let’s create a realm in Keycloak once you login as an administrator.
Once we create a realm, we don’t need to do anything yet. We will use Realm to set up our service provider later.
In the next step, we will configure another identity provider.
Configure Identity Provider in Keycloak
You can use Keycloak as an identity provider for SSO. But in this demo, Keycloak is acting as an identity broker. We will use saml-idp as an identity provider. This is a simple node-based SAML identity provider for development purposes. You can read about it more here.
npm install -g saml-idp.
Use the below command to start this identity provider. It will run on port 7000 by default.
Now if we access http://localhost:7000 , the identity provider will be running and we can see the metadata in the browser. We can download this metadata to configure in Keycloak.
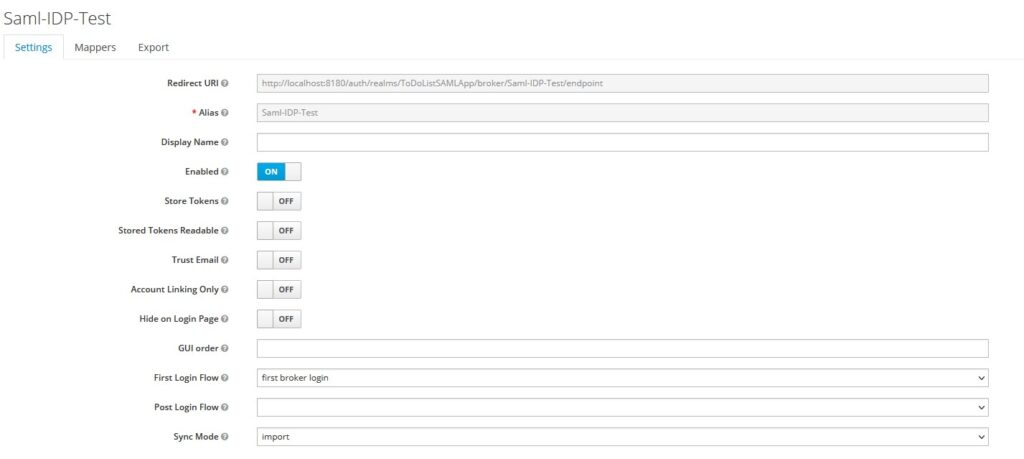
Let’s create an identity provider (SAML Version 2.0).
Enter an alias and Redirect URI
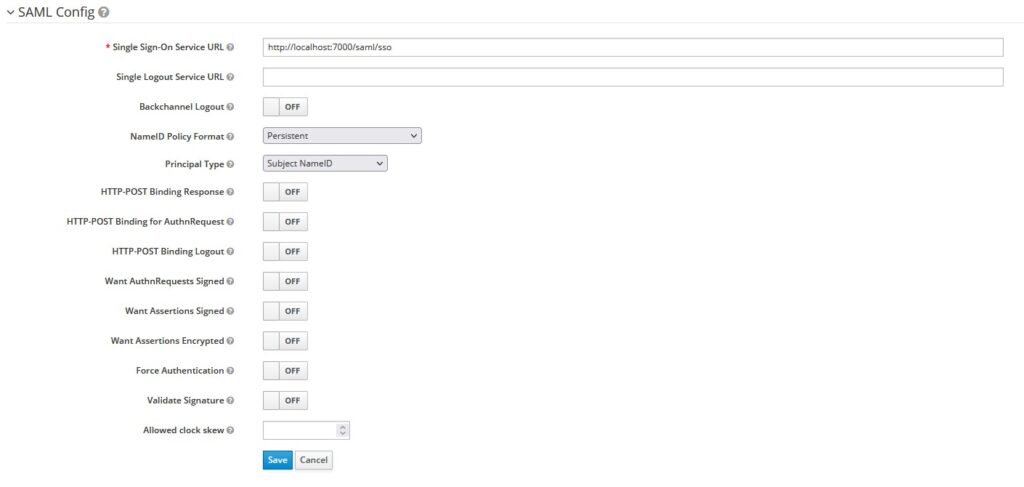
Let’s configure the SAML Identity provider’s details in Keycloak.
SSO URL – http://localhost:7000/saml/sso
Save the configuration. Now you should be able to download Keycloak’s metadata that you can import into the identity provider (saml-idp).
Next, we configure the service provider application.
Configure Service Provider in Keycloak
We already have written a spring boot application that we will use as a service provider. If you want to learn more about the Spring Boot application, you can follow this previous post.
Create a new client under our realm in Keycloak
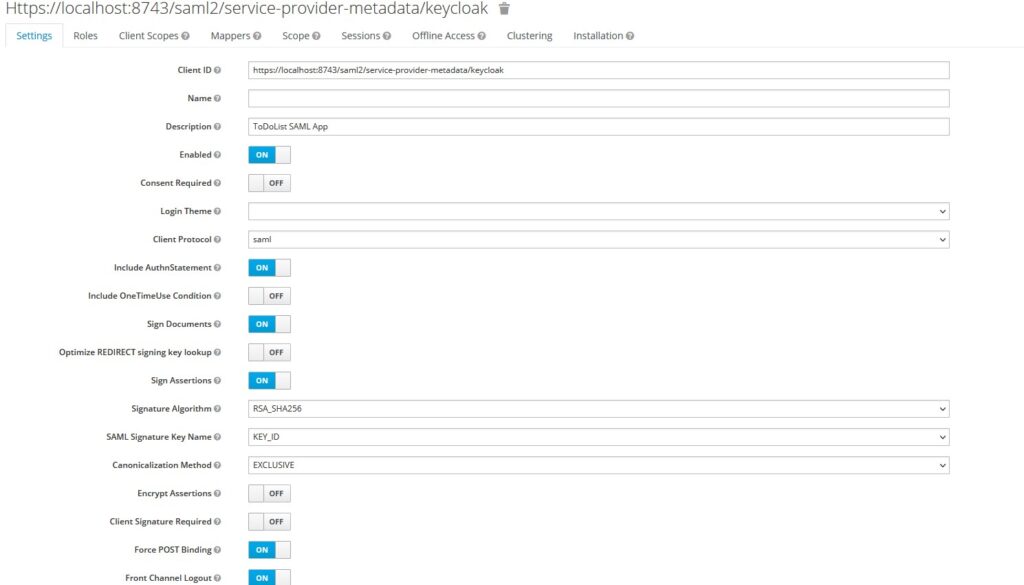
Provide a client id as https://localhost:8743/saml2/service-provider-metadata/keycloak
Enter Name and Description for the client
Select SAMLas a protocol under Client Protocol
Enable include authnstatements, sign documents, and sign assertions
Start the spring boot application once you configure the properties.
Demo of Keycloak as Identity Broker
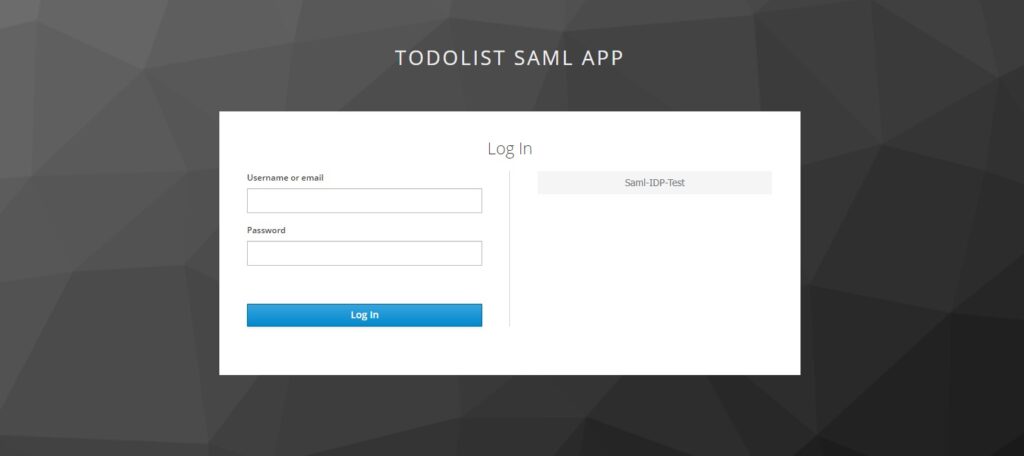
Assuming we are running Spring Boot Application, Keycloak, and another identity provider (saml-idp), now we can run the demo by accessing the Spring Boot Application.
You can select the identity provider Saml-IDP-Test and it will redirect to that identity provider.
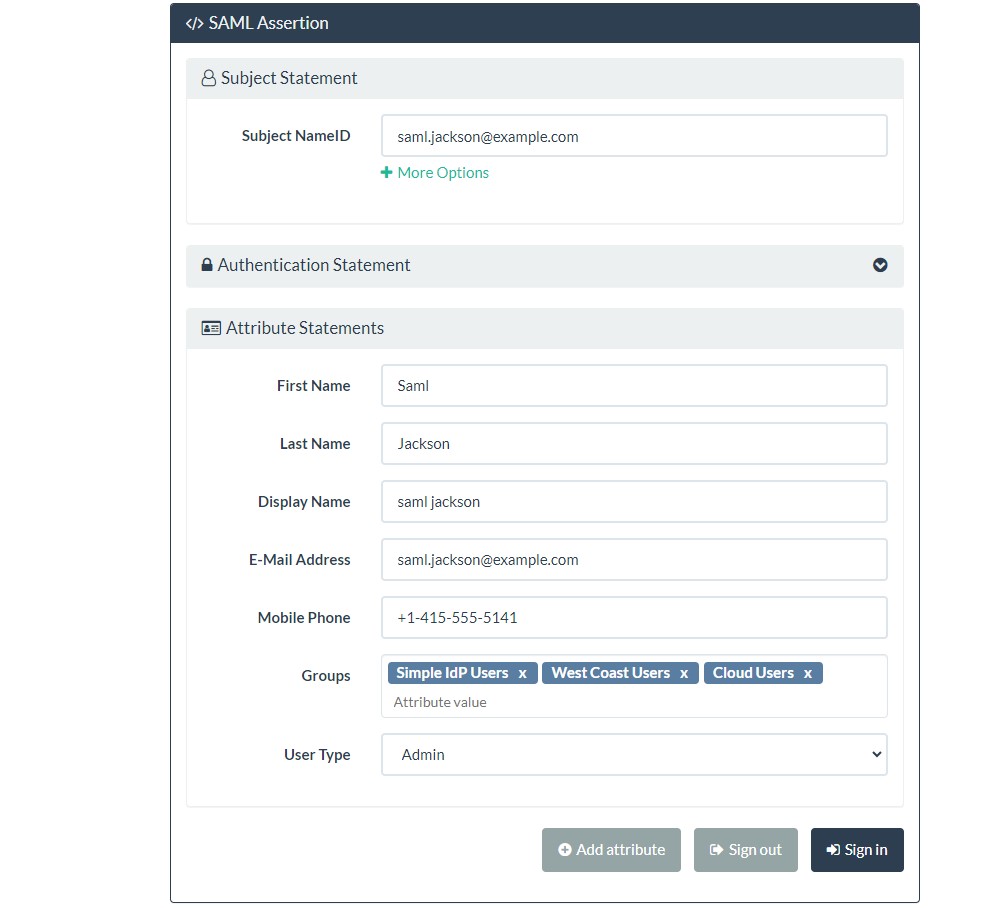
Once you select Sign In option, it will redirect you back to service provider application if the user already exists in Keycloak. If the user does not exist in Keycloak, keycloak will ask to enter minimal attributes and it will create that user dynamically (JIT Provisioning).
And this way, the user was able to log in successfully.
Conclusion
In this post, I showed how to use Keycloak as an identity broker with another identity provider. Keycloak is a very well-documented SSO provider. If you have any questions or feedback, please do send me questions.