In this post, we will learn about Spring Cloud Function and will deploy an example of Spring Cloud Function on AWS Lambda. By end of this post, we will have more understanding of serverless functions. If you want to learn more about serverless architecture, this post will get you started.
What is Spring Cloud Function?
Spring Cloud Function is one of the features of Spring Cloud. It allows developers to write cloud-agnostic functions with Spring features. These functions can be stand-alone classes and one can easily deploy on any cloud platform to build a serverless framework. Spring Cloud offers a library spring-cloud-starter-function-web allows to build functions with Spring features and it brings all the necessary dependencies.
Why use Spring Cloud Function?
This question is more when to use Spring Cloud Function. Basically, Spring Cloud Function library allows to the creation of functional applications that can be deployed easily on AWS Lambda. These functions follow the Java 8 pattern of Supplier, Consumer, and Function.
spring-cloud-starter-function-web library provides native interaction for handling requests, streams.
Features of Spring Cloud Function
The major advantage of Spring Cloud Function is it provides all the features of Spring Boot like autoconfiguration, dependency injection. But there are more features:
- Transparent type conversions of input and output
- POJO Functions
- REST Support to expose functions as HTTP endpoints
- Streaming data to/from functions via Spring Cloud Stream framework
- Deploying functions as isolated jar files
- Adapter for AWS Lambda, Google Cloud Platform, Microsoft Azure
Demo
As part of this post, we will create Spring Cloud Function and deploy it in AWS Lambda. Once we create a regular spring boot application, add the following dependencies in your Gradle file:
dependencies {
implementation 'org.springframework.boot:spring-boot-starter'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.cloud:spring-cloud-function-adapter-aws:3.2.1'
implementation "com.amazonaws:aws-lambda-java-events:${awsLambdaEventsVersion}"
implementation "com.amazonaws:aws-lambda-java-core:${awsLambdaCoreVersion}"
runtimeOnly 'com.h2database:h2'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
Note the dependency spring-cloud-function-adapter-aws allows us to integrate Spring Cloud Function with AWS Lambda.
One main class for the application will look like below:
package com.betterjavacode.springcloudfunctiondemo;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.function.context.FunctionalSpringApplication;
@SpringBootApplication
public class SpringcloudfunctiondemoApplication {
public static void main(String[] args) {
FunctionalSpringApplication.run(SpringcloudfunctiondemoApplication.class, args);
}
}
Compare this to a regular Spring Boot application, there is one difference. We are using FunctionalSpringApplication as an entry point. This is a functional approach to writing beans and helps with startup time.
Now, we can write three types of functions Function, Consumer OR Supplier. We will see what each function does and how we can use as part of this demo.
Furthermore, let’s create a POJO model class Customer.
package com.betterjavacode.springcloudfunctiondemo.models;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name= "customer")
public class Customer
{
@Id
@GeneratedValue(generator = "UUID")
private Long id;
private String name;
private int customerIdentifier;
private String email;
private String contactPerson;
public Customer(String name, int customerIdentifier, String email, String contactPerson)
{
this.name = name;
this.customerIdentifier = customerIdentifier;
this.email = email;
this.contactPerson = contactPerson;
}
public String getName ()
{
return name;
}
public void setName (String name)
{
this.name = name;
}
public int getCustomerIdentifier ()
{
return customerIdentifier;
}
public void setCustomerIdentifier (int customerIdentifier)
{
this.customerIdentifier = customerIdentifier;
}
public String getEmail ()
{
return email;
}
public void setEmail (String email)
{
this.email = email;
}
public String getContactPerson ()
{
return contactPerson;
}
public void setContactPerson (String contactPerson)
{
this.contactPerson = contactPerson;
}
public Long getId ()
{
return id;
}
public void setId (Long id)
{
this.id = id;
}
}
Certainly, our spring cloud function will perform some business logic related to this model Customer.
Consumer Function
Let’s create a Consumer function. Consumer function usually takes an input and performs some business logic that will have a side-effect on the data. It will not produce any output. So it is more like a void method.
For our demo, it will look like below:
package com.betterjavacode.springcloudfunctiondemo.functions;
import com.betterjavacode.springcloudfunctiondemo.models.Customer;
import com.betterjavacode.springcloudfunctiondemo.repositories.CustomerRepository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.Map;
import java.util.function.Consumer;
@Component
public class CustomerConsumer implements Consumer<Map<String, String>>
{
public static final Logger LOGGER = LoggerFactory.getLogger(CustomerConsumer.class);
@Autowired
private CustomerRepository customerRepository;
@Override
public void accept (Map<String, String> map)
{
LOGGER.info("Creating the customer", map);
Customer customer = new Customer(map.get("name"), Integer.parseInt(map.get(
"customerIdentifier")), map.get("email"), map.get("contactPerson"));
customerRepository.save(customer);
}
}
This CustomerConsumer function implements Consumer function type and takes an input of type Map<String, String>. As part of the interface contract, one needs to implement the method accept. This method will take map input and perform some business logic. One thing to understand is that Spring Cloud Function will handle type conversion from raw input stream and types declared by the function. If the function is not able to infer tye information, it will convert to a generic type of map.
This function takes a map of DTO object for the customer and saves it in the database. For the database, we are using H2 in-memory database. One can always add more business logic, but for demo purposes, we are showing a simple example.
Supplier Function
The supplier function acts like a GET endpoint. This function takes no input but returns data.
package com.betterjavacode.springcloudfunctiondemo.functions;
import com.betterjavacode.springcloudfunctiondemo.models.Customer;
import com.betterjavacode.springcloudfunctiondemo.repositories.CustomerRepository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.function.Supplier;
@Component
public class CustomerSupplier implements Supplier
{
public static final Logger LOGGER = LoggerFactory.getLogger(CustomerSupplier.class);
@Autowired
private CustomerRepository customerRepository;
@Override
public Customer get ()
{
List customers = customerRepository.findAll();
LOGGER.info("Getting the customer of our choice - ", customers);
return customers.get(0);
}
}
Configuring Spring Cloud Function with AWS Lambda
One AWS Lambda will execute only one function. If there are multiple Spring Cloud Function beans, one can configure which function to execute through a lambda. Add the property in application.properties as follows:
spring.cloud.function.definition=customerConsumer
One can easily deploy a single jar file with AWS Lambda and use Spring Profiles to pass different functions in application.properties.
Building Shaded Jar
To deploy the application in AWS Lambda with Spring Cloud Function, you will need a shaded jar. To build this jar, we will use gradle shadow plugin. The build file will look like below:
buildscript {
ext {
springBootVersion = '2.6.2'
wrapperVersion = '1.0.17.RELEASE'
shadowVersion = '5.1.0'
}
repositories {
mavenLocal()
jcenter()
mavenCentral()
maven { url "https://repo.spring.io/snapshot" }
maven { url "https://repo.spring.io/milestone" }
}
dependencies {
classpath "com.github.jengelman.gradle.plugins:shadow:${shadowVersion}"
classpath("org.springframework.boot.experimental:spring-boot-thin-gradle-plugin:${wrapperVersion}")
classpath("org.springframework.boot:spring-boot-gradle-plugin:${springBootVersion}")
classpath("io.spring.gradle:dependency-management-plugin:1.0.8.RELEASE")
}
}
apply plugin: 'java'
apply plugin: 'maven-publish'
apply plugin: 'eclipse'
apply plugin: 'com.github.johnrengelman.shadow'
apply plugin: 'org.springframework.boot'
apply plugin: 'io.spring.dependency-management'
group = 'com.betterjavacode'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
targetCompatibility = '1.8'
repositories {
mavenLocal()
mavenCentral()
maven { url "https://repo.spring.io/snapshot" }
maven { url "https://repo.spring.io/milestone" }
}
ext {
springCloudFunctionVersion = "3.2.1"
awsLambdaEventsVersion = "2.0.2"
awsLambdaCoreVersion = "1.2.1"
}
assemble.dependsOn = [shadowJar]
jar {
manifest {
attributes 'Main-Class': 'com.betterjavacode.springcloudfunctiondemo.SpringcloudfunctiondemoApplication'
}
}
import com.github.jengelman.gradle.plugins.shadow.transformers.*
shadowJar {
classifier = 'aws'
dependencies {
exclude(
dependency("org.springframework.cloud:spring-cloud-function-web:${springCloudFunctionVersion}"))
}
// Required for Spring
mergeServiceFiles()
append 'META-INF/spring.handlers'
append 'META-INF/spring.schemas'
append 'META-INF/spring.tooling'
transform(PropertiesFileTransformer) {
paths = ['META-INF/spring.factories']
mergeStrategy = "append"
}
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-function-dependencies:${springCloudFunctionVersion}"
}
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.cloud:spring-cloud-function-adapter-aws:3.2.1'
implementation "com.amazonaws:aws-lambda-java-events:${awsLambdaEventsVersion}"
implementation "com.amazonaws:aws-lambda-java-core:${awsLambdaCoreVersion}"
runtimeOnly 'com.h2database:h2'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
test {
useJUnitPlatform()
}
Run the command ./gradlew clean build and it will build a shaded jar. An Uber Jar contains the contents of multiple jars from dependencies. A shaded jar provides a way of creating an uber jar and renaming the packages from Uber Jar. Now to deploy our jar in AWS Lambda, we have to make sure to include a dependency com.amazonaws:aws-lambda-java-core.
Creating an AWS Lambda in AWS
Regardless, let’s create an AWS Lambda in AWS.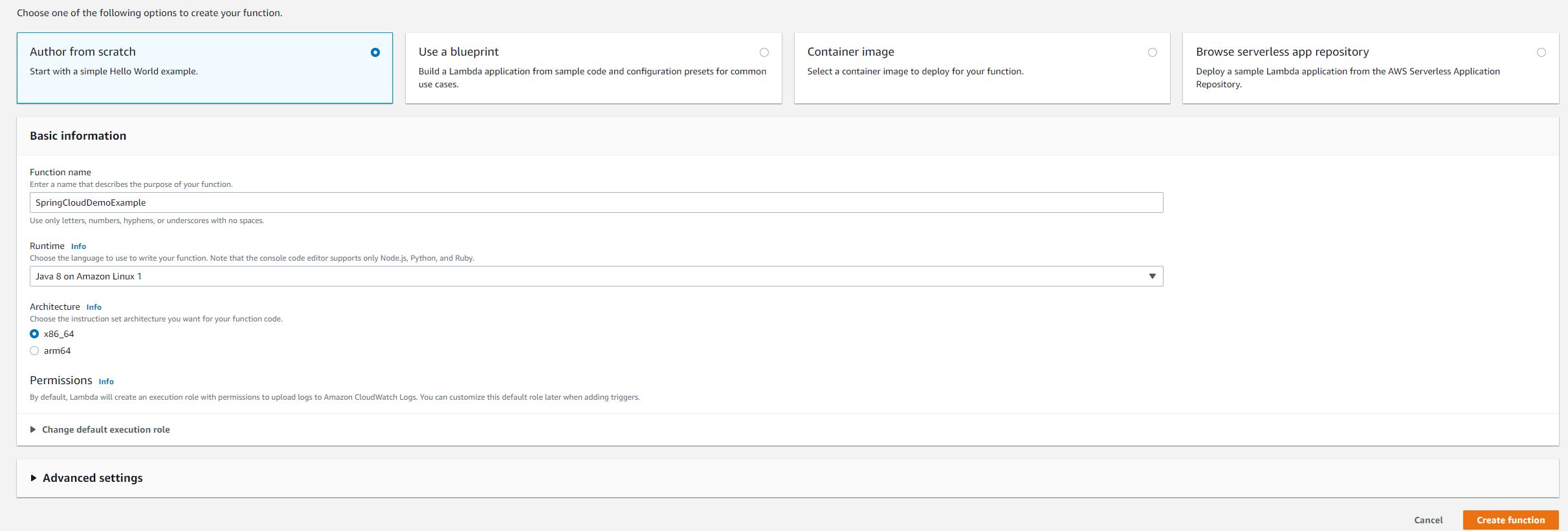

Provide a descriptive name – SpringCloudFunctionDemo.
Upload the shaded jar.
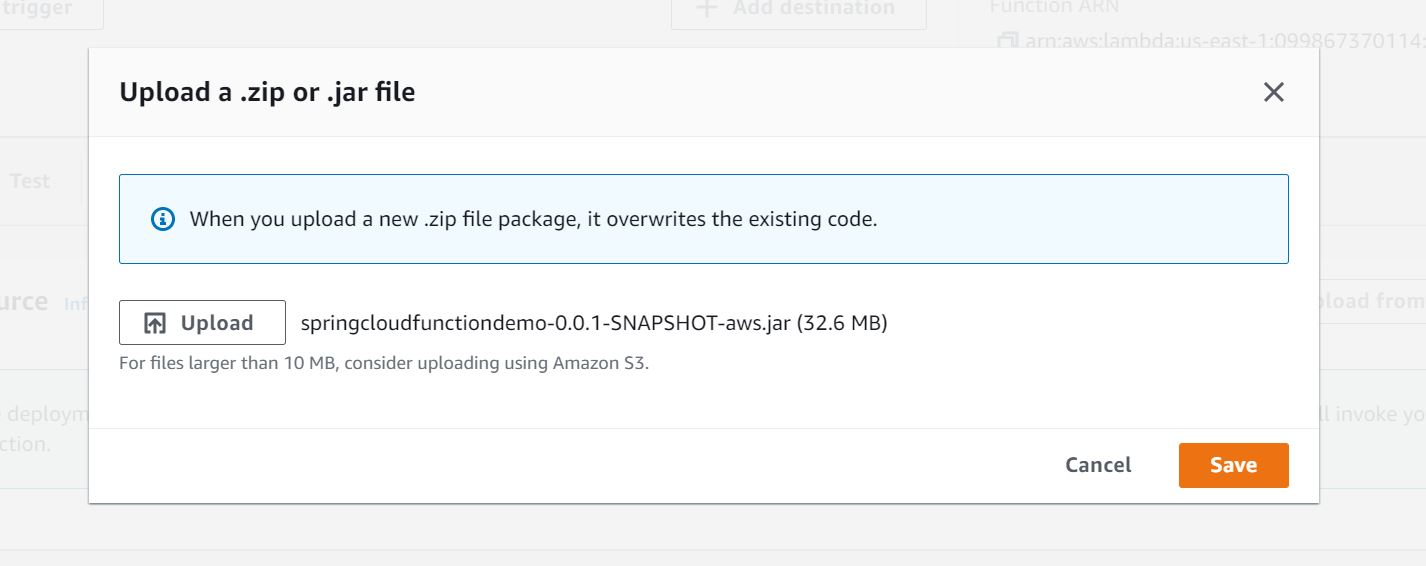

Now update Runtime Settings in AWS Lambda to indicate how the lambda will invoke our function. Spring provides a classFunctionInvoker with generic method handleRequest as part of the library spring-cloud-function-aws-adapter.


Now if we run the AWS Lambda, we will see the execution of our consumer function. We will test our consumer function with a JSON data load:
{
"name": "ABC Company",
"customerIdentifier": "1",
"email": "support@abccompany.com",
"contactPerson": "John Doe"
}
2022-01-23 06:45:08.987 INFO 9 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
2022-01-23 06:45:09.391 INFO 9 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
2022-01-23 06:45:09.455 INFO 9 --- [ main] org.hibernate.dialect.Dialect : HHH000400: Using dialect: org.hibernate.dialect.H2Dialect
2022-01-23 06:45:10.289 INFO 9 --- [ main] org.hibernate.tuple.PojoInstantiator : HHH000182: No default (no-argument) constructor for class: com.betterjavacode.springcloudfunctiondemo.models.Customer (class must be instantiated by Interceptor)
2022-01-23 06:45:10.777 INFO 9 --- [ main] o.h.e.t.j.p.i.JtaPlatformInitiator : HHH000490: Using JtaPlatform implementation: [org.hibernate.engine.transaction.jta.platform.internal.NoJtaPlatform]
2022-01-23 06:45:10.800 INFO 9 --- [ main] j.LocalContainerEntityManagerFactoryBean : Initialized JPA EntityManagerFactory for persistence unit 'default'
2022-01-23 06:45:12.832 INFO 9 --- [ main] lambdainternal.LambdaRTEntry : Started LambdaRTEntry in 8.239 seconds (JVM running for 8.868)
2022-01-23 06:45:12.919 INFO 9 --- [ main] o.s.c.f.adapter.aws.FunctionInvoker : Locating function: 'customerConsumer'
2022-01-23 06:45:12.931 INFO 9 --- [ main] o.s.c.f.adapter.aws.FunctionInvoker : Located function: 'customerConsumer'
2022-01-23 06:45:12.940 INFO 9 --- [ main] o.s.c.f.adapter.aws.FunctionInvoker : Received: {"name":"ABC Company","customerIdentifier":"1","email":"support@abccompany.com","contactPerson":"John Doe"}
2022-01-23 06:45:13.146 INFO 9 --- [ main] o.s.c.f.adapter.aws.AWSLambdaUtils : Incoming JSON Event: {"name":"ABC Company","customerIdentifier":"1","email":"support@abccompany.com","contactPerson":"John Doe"}
2022-01-23 06:45:13.146 INFO 9 --- [ main] o.s.c.f.adapter.aws.AWSLambdaUtils : Incoming MAP: {name=ABC Company, customerIdentifier=1, email=support@abccompany.com, contactPerson=John Doe}
2022-01-23 06:45:13.166 INFO 9 --- [ main] o.s.c.f.adapter.aws.AWSLambdaUtils : Incoming request headers: {id=042ab9bc-211d-fa47-839c-888720ec35d4, timestamp=1642920313144}
2022-01-23 06:45:13.184 INFO 9 --- [ main] c.b.s.functions.CustomerConsumer : Creating the customer
END RequestId: b8352114-77f6-414c-a2dc-63d522a9eef4
REPORT RequestId: b8352114-77f6-414c-a2dc-63d522a9eef4 Duration: 710.53 ms Billed Duration: 711 ms Memory Size: 512 MB Max Memory Used: 251 MB Init Duration: 8986.65 ms
As you can see in the above log, there is a log Creating the customer from our code. Also, you will see the response as Ok from Lambda execution.
The code for this demo is available here.
Conclusion
AWS Lambda is a very powerful service to build a serverless framework. With the combination of Spring Cloud and AWS, one can leverage multiple features to build simpler services for handling complex business requirements. Here is another post about connecting Spring Boot application with AWS Dynamo DB.