In this post, I will show how I added file upload functionality in my Spring Boot application, social KPI.
On the outskirts, it looks very simple functionality and it is indeed simple with Spring Boot. As part of this post, we will build a web form where an administrator will add additional users for his/her company by importing a CSV file in a particular format.
Basic functionality is to provide a way for an administrator to import a CSV file, read and validate the data, and save it in the database if proper data.
Now once we have defined our user story, let’s get started with the post.
Form For File Upload In a Spring Boot Application
We are using thymeleaf templates for our spring boot based application. So writing a simple html page with a form to upload a file is very straight forward as below:
<div class="container importuser">
<div class="form-group">
<form method="POST" th:action="@{/uploadUsers}" enctype="multipart/form-data">
<input type="hidden" name="companyGuid" th:value="${companyGuid}"/>
<input type="file" name="file"/></br></br>
<button type="submit" class="btn btn-primary btn-lg" value="Import">Import
</button>
</form>
</div>
</div>
As you see in this form, clicking on Import button will kick the action to upload users.
Controller to handle file upload on backend side
A controller to handle upload users functionality will look like below:
@RequestMapping(value = "/uploadUsers",method= RequestMethod.POST)
public String fileUpload (@RequestParam("file") MultipartFile file, @RequestParam(
"companyGuid") String companyGuid,
RedirectAttributes redirectAttributes)
{
LOGGER.info("File is {}", file.getName());
LOGGER.info("Company Guid is {}", companyGuid);
if (file.isEmpty())
{
redirectAttributes.addFlashAttribute("message", "Please select a file to upload");
return "redirect:/uploadStatus";
}
List userList = FileUtil.readAndValidateFile(file, roleRepository);
for(User user: userList)
{
User createdUser = userManager.createUser(companyGuid, user);
}
redirectAttributes.addFlashAttribute("message",
"You successfully uploaded " + file.getOriginalFilename() + " and added " + userList.size() + " users");
return "redirect:/uploadStatus";
}
The method to readAndValidateFile is simply reading the data from file, validating to make sure all the fields in CSV file exists, if wrong format, it will throw an error. If a valid file, it will create a list of users. UserManager will create each user.
The class FileUtil is as below:
package com.betterjavacode.socialpie.utils;
import com.betterjavacode.socialpie.models.Role;
import com.betterjavacode.socialpie.models.User;
import com.betterjavacode.socialpie.repositories.RoleRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.multipart.MultipartFile;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
public class FileUtil
{
private static final String FIRST_NAME = "firstname";
private static final String LAST_NAME = "lastname";
public static List readAndValidateFile (MultipartFile file, RoleRepository roleRepository)
{
BufferedReader bufferedReader;
List result = new ArrayList<>();
try
{
String line;
InputStream inputStream = file.getInputStream();
bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
while((line = bufferedReader.readLine()) != null)
{
String[] userData = line.split(",");
if(userData == null || userData.length != 5)
{
throw new RuntimeException("File data not in correct format");
}
if(FIRST_NAME.equalsIgnoreCase(userData[0]) && LAST_NAME.equalsIgnoreCase(userData[2]))
{
continue; // first line is header
}
User user = new User();
user.setFirstName(userData[0]);
user.setMiddleName(userData[1]);
user.setLastName(userData[2]);
user.setEmail(userData[3]);
Role role = roleRepository.findByRoleName(userData[4]);
user.setRole(role);
result.add(user);
}
}
catch(IOException e)
{
throw new RuntimeException("Unable to open the file " + e.getMessage());
}
return result;
}
}
A working demo
Once I log into the application Social KPI, I click on Add Users and it will take me to upload the users screen which will look below:

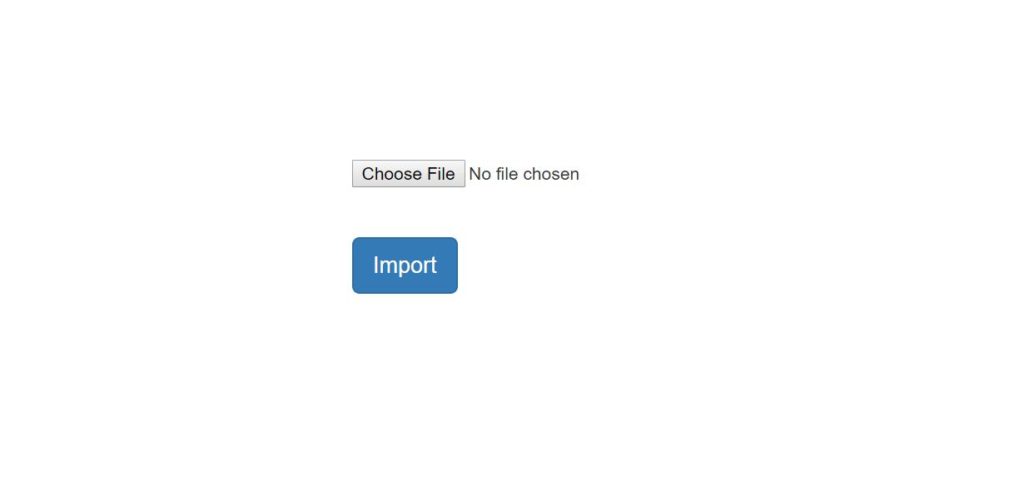
Import Users
Once you choose a file in CSV format to upload and click on Import, it will show the screen as below:

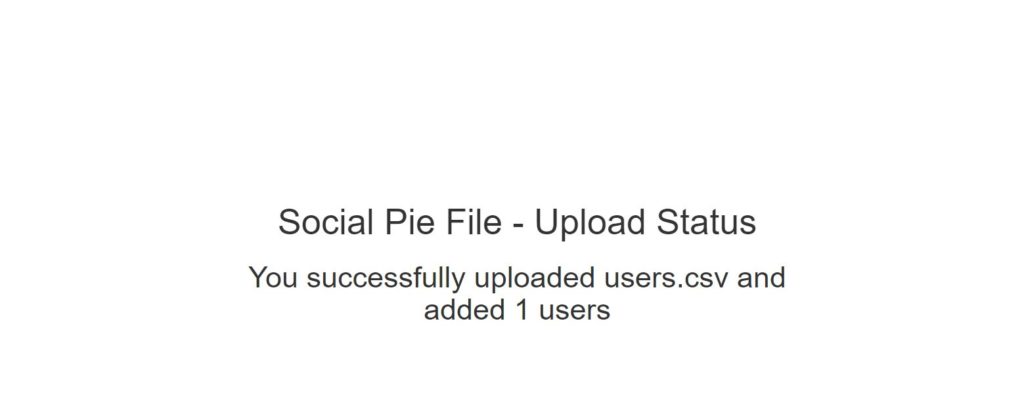
File Upload Status
Conclusion
So in this post, we showed how to import a file while using Spring Boot multipart form.
References
- Uploading files – uploading files