In this post, I cover everything you need to know about Spring Data JPA so you can use this library more confidently in your Spring Boot application. I have seen there are a lot of confusion about when to use CrudRepository or JpaRepository, so I will cover that as well.
What is Spring Data JPA?
As the official documentation from Spring says “Spring Data JPA makes it easy to implement JPA based repositories. It improves and eases the implementation of the JPA-based data access layer. Overall, data access applications are easier to implement.”
With Spring Data JPA, one can avoid a lot of boilerplate code for Java Persistent API (JPA) in the application. The library also makes it easy to query the data from the database taking away a lot of implementation for SQL queries from a developer.
As a developer, you only write repository interfaces including any custom methods and Spring Data JPA will provide the most implementation automatically.
When to use Spring Data JPA?
When to use Spring Data JPA actually depends on your use case. But most Spring applications will need data objects. And if you have data objects, you will need a way to access them, and use them for transactions.
If you are building a database-based web application, then you will end up creating objects that represent your database entities. When one layer accesses these objects or creates the data to store in the database, you will need access APIs. You can implement repository interfaces and it will provide the basic CRUD operations. A programmer doesn’t even have to implement any of these interface methods.
You can also add a custom method in these repository interfaces.
- Create a new method in the interface
- Write the JPQL query with an annotation
@Queryat the beginning of the query. - One can also write JPA Named queries
Some other major features of Spring Data JPA are:
- Auditing of domain classes
- Useful in batch loading, dynamical queries
- Support for XML Mapping of entities
Details of the Spring Data JPA library
In your application, you can include the dependency easily as follows:
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
Now to enable your JPA repositories, add the following annotation to your main application class:
@EnableJpaRepositories(basePackages = "com.betterjavacode.modelmapperdemo")
Now to add a repository for any of your domain objects, you can create an interface extending JpaRepository or CrudRepository.
This will look like below:
@Repository
public interface OrderRepository extends JpaRepository<Order, Long>
{
List findAllByCustomer (Customer customer);
}
As you can see above, we have added a new interface that represents a domain object of Order. I have also added a custom method findAllByCustomer. JPA Named Queries will take care of the implementation of this method to fetch all the orders by a customer.
Configuration
Spring Boot configures Hibernate as the default JPA provider. If you want to customize this configuration or change the default JPA provider, you will have to create a entityManagerFactory bean in your Spring Configuration.
@Configuration
@EnableTransactionManagement
@EnableJpaRepositories("com.betterjavacode.modelmapperdemo")
@PropertySource("classpath:application.properties")
public class DataConfig {
private final String PROPERTY_DRIVER = "driver";
private final String PROPERTY_URL = "url";
private final String PROPERTY_USERNAME = "user";
private final String PROPERTY_PASSWORD = "password";
private final String PROPERTY_SHOW_SQL = "hibernate.show_sql";
private final String PROPERTY_DIALECT = "hibernate.dialect";
@Autowired
Environment environment;
@Bean
LocalContainerEntityManagerFactoryBean entityManagerFactory() {
LocalContainerEntityManagerFactoryBean lfb = new LocalContainerEntityManagerFactoryBean();
lfb.setDataSource(dataSource());
lfb.setPersistenceProviderClass(HibernatePersistence.class);
lfb.setPackagesToScan("com.betterjavacode.modelmapperdemo");
lfb.setJpaProperties(hibernateProps());
return lfb;
}
@Bean
DataSource dataSource() {
DriverManagerDataSource ds = new DriverManagerDataSource();
ds.setUrl(environment.getProperty(PROPERTY_URL));
ds.setUsername(environment.getProperty(PROPERTY_USERNAME));
ds.setPassword(environment.getProperty(PROPERTY_PASSWORD));
ds.setDriverClassName(environment.getProperty(PROPERTY_DRIVER));
return ds;
}
Properties hibernateProps() {
Properties properties = new Properties();
properties.setProperty(PROPERTY_DIALECT, environment.getProperty(PROPERTY_DIALECT));
properties.setProperty(PROPERTY_SHOW_SQL, environment.getProperty(PROPERTY_SHOW_SQL));
return properties;
}
@Bean
JpaTransactionManager transactionManager() {
JpaTransactionManager transactionManager = new JpaTransactionManager();
transactionManager.setEntityManagerFactory(entityManagerFactory().getObject());
return transactionManager;
}
}
The above code shows how to add configuration if you plan to customize the default hibernation configuration.
@EnableTransactionManagement– enables the transactions in the application, especially when creating or updating the data.@PropertySource– reads the application properties that will be used in Datasource bean.
As mentioned previously, Spring Boot uses Hibernate as the default persistence provider. But there are few other persistence providers available like OpenJPA or EclipseLink.
Difference between CrudRepository and JpaRepository
We previously discussed about creating repository interfaces that extend JpaRepository or CrudRepository. But when do you use which one? In this section, I clarify more details about these repository interfaces.
CrudRepository is the base interface. JpaRepository extends PagingAndSortingRepository which in turn extends CrudRepository.
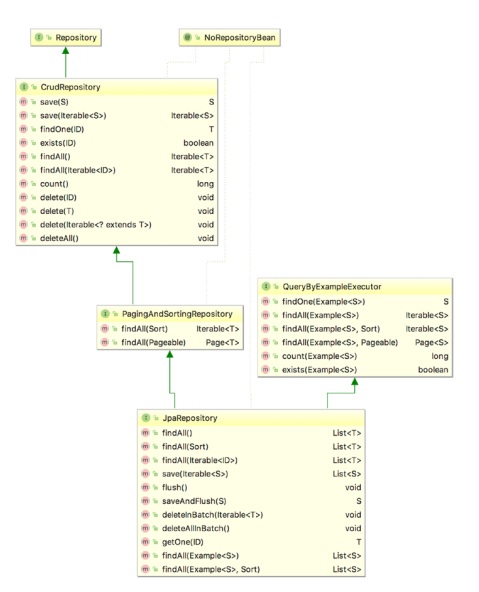
CrudRepository– This provides CRUD functions.PagingAndSortingRepository– This provides functions for sortable and pageable data.JpaRepository– JpaRepository provides JPA-related functions to flush the persistence context as well as delete data in a batch.
In short, one can use JpaRepository as it will include all the other methods from CrudRepository and PagingAndSortingRepository.
Conclusion
In this post, I showed the details of Spring Data JPA library and how to use it. I also showed configuration details and what repository interface to use.
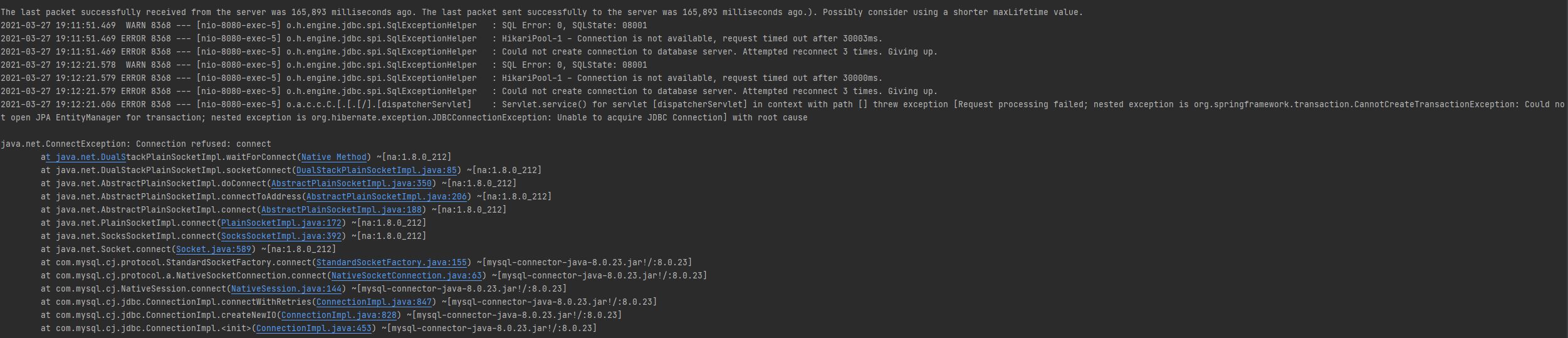 As you can see in the above screenshot, there were two attempts to retry. In each retry, it tried to connect to MySQL server thrice.
As you can see in the above screenshot, there were two attempts to retry. In each retry, it tried to connect to MySQL server thrice.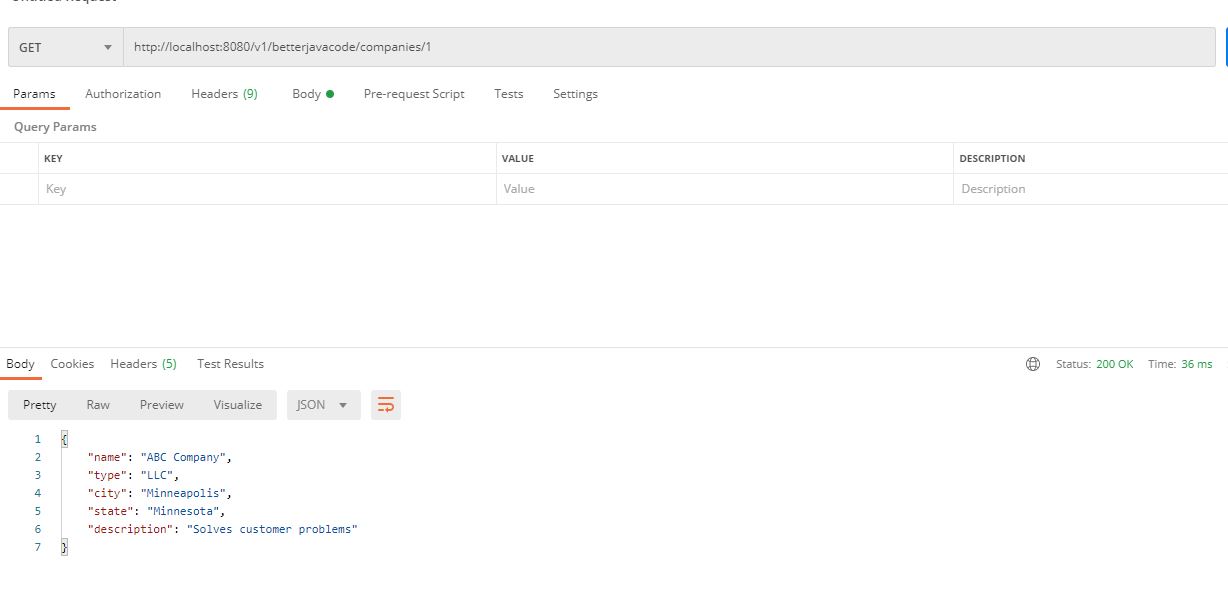

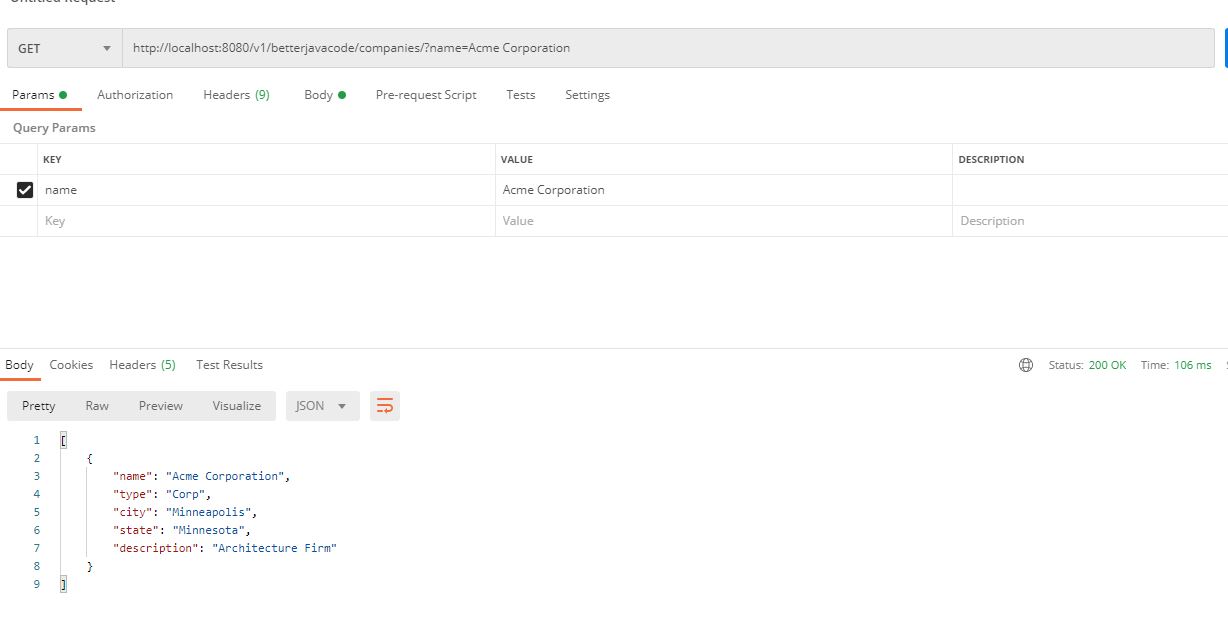

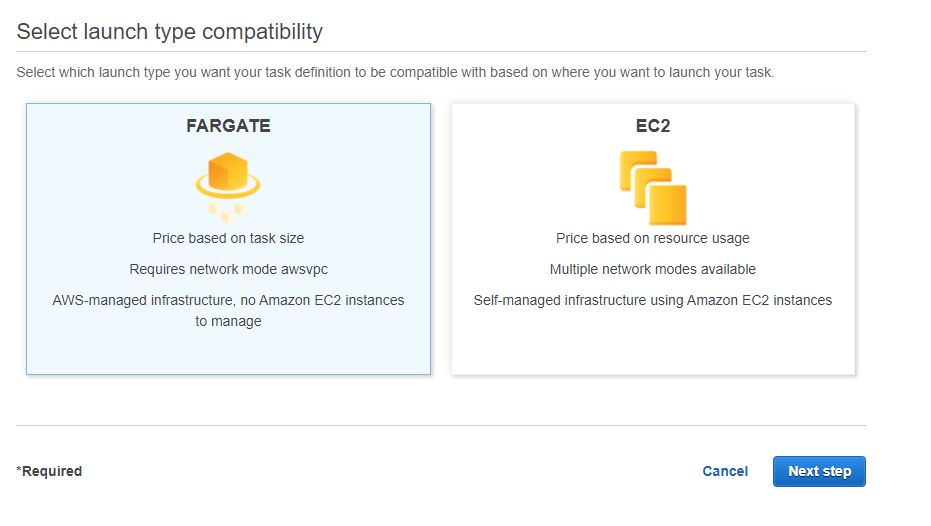
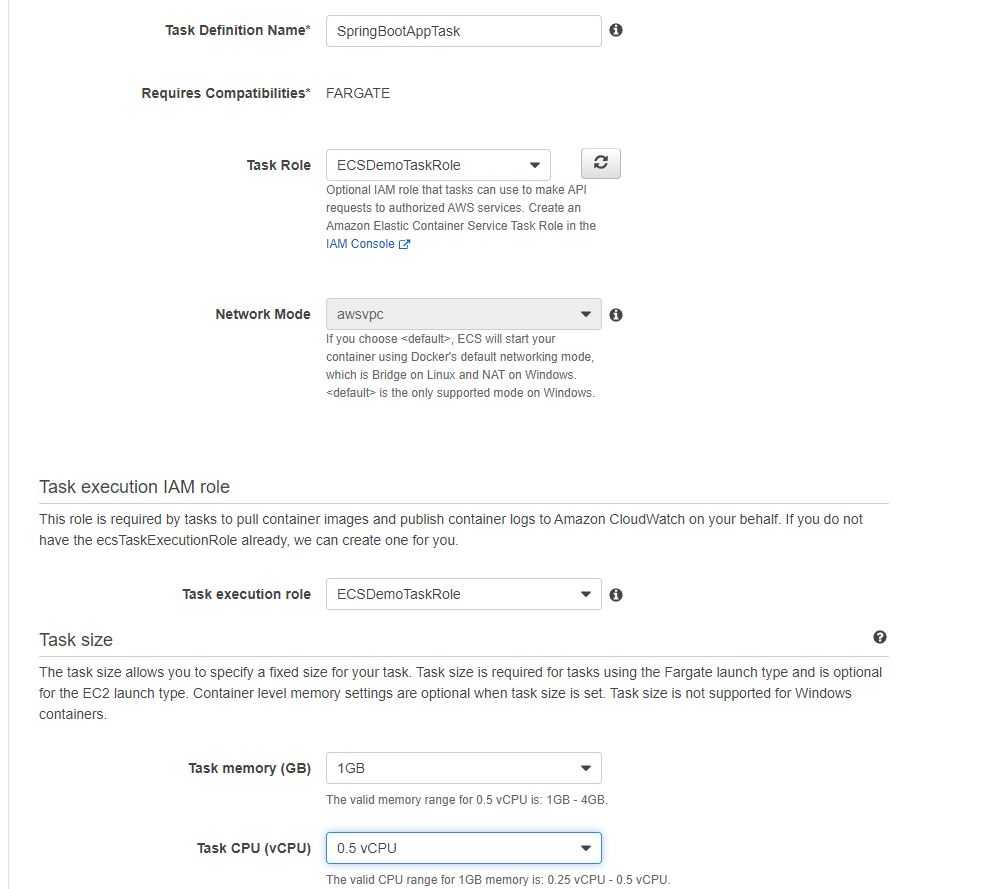 Also remember to create a IAM role beforehand which should have a permission policy `
Also remember to create a IAM role beforehand which should have a permission policy `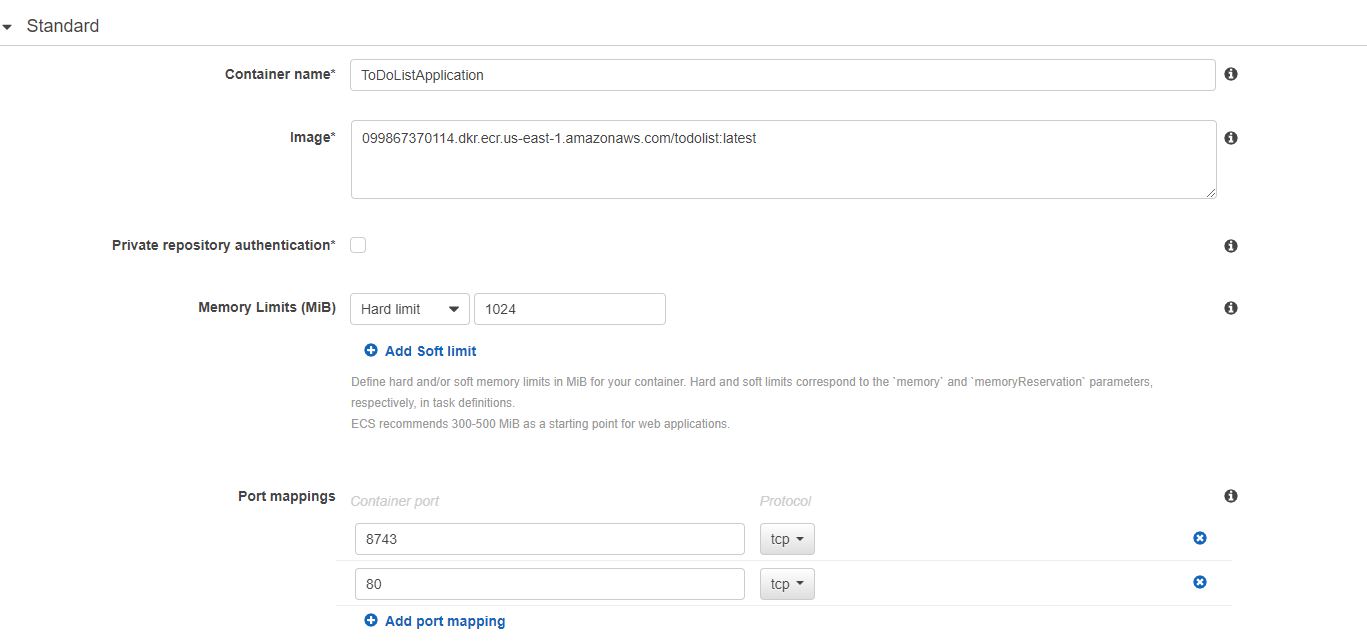 We have mapped two ports 8743 and 80 from our host to the container. In the same container, also add environment properties if you want to override properties for your data source. These properties include
We have mapped two ports 8743 and 80 from our host to the container. In the same container, also add environment properties if you want to override properties for your data source. These properties include  As you see, we have chosen a AWS Fargate based cluster. On the next step you provide a name for the cluster and click “Create” and that should create a cluster.
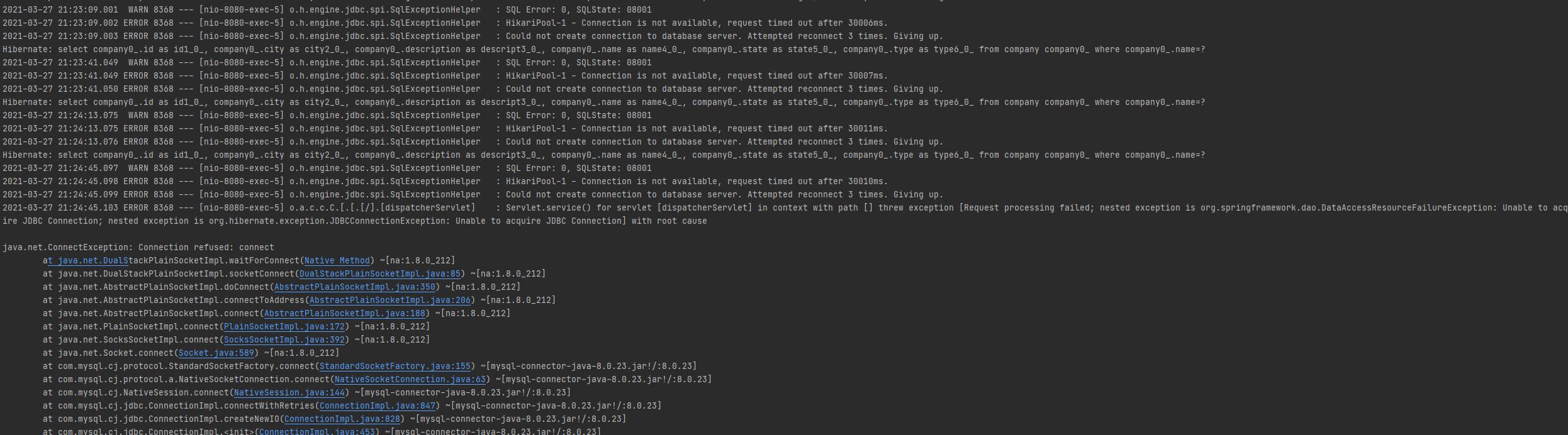
As you see, we have chosen a AWS Fargate based cluster. On the next step you provide a name for the cluster and click “Create” and that should create a cluster.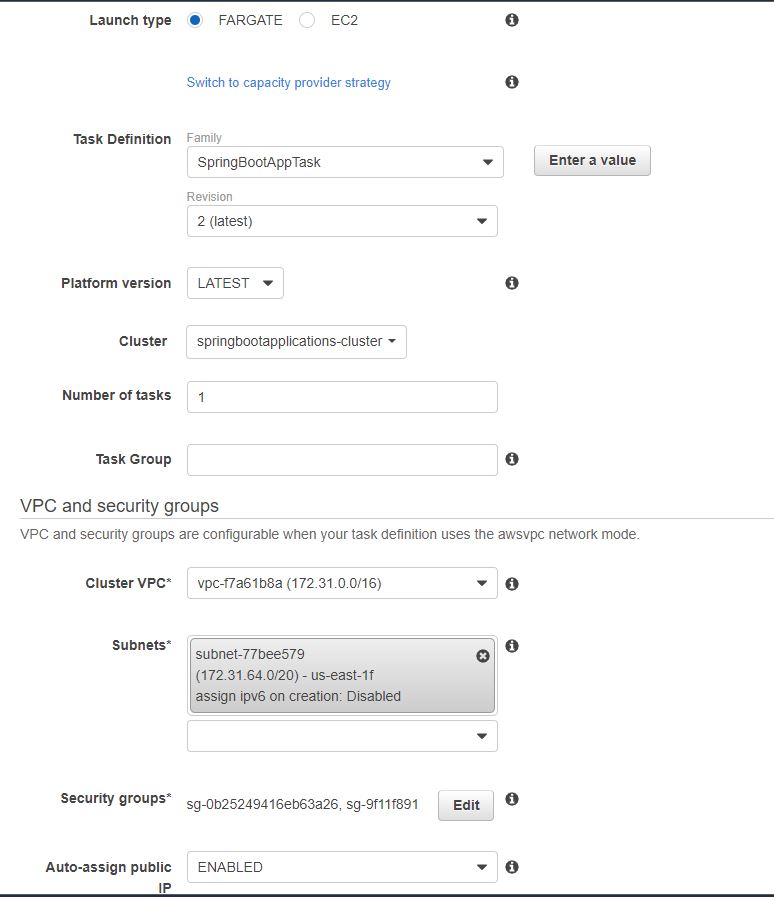 We have security groups defined here, but it also provides the option to create a new security group when running. In this security group, you should choose which type of protocol and ports you want to allow for access. In this case, we want our port 8743 for internet and TCP. Now click ‘Run Task’ and that should start the task. Once the task starts, we will be able to see the logs from cloud watch as below:
We have security groups defined here, but it also provides the option to create a new security group when running. In this security group, you should choose which type of protocol and ports you want to allow for access. In this case, we want our port 8743 for internet and TCP. Now click ‘Run Task’ and that should start the task. Once the task starts, we will be able to see the logs from cloud watch as below: 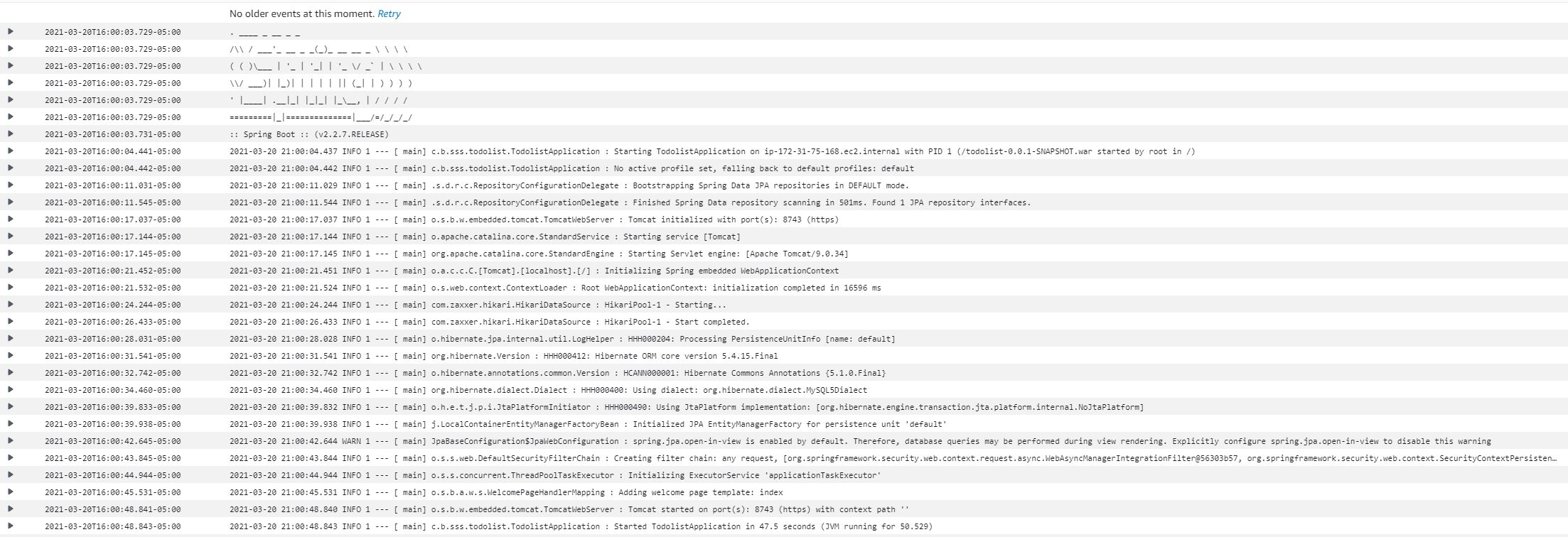 On this basis, if you look at logs, now our application is running successfully on port 8743. Now we can access the application using the public IP that the Fargate task provided.
On this basis, if you look at logs, now our application is running successfully on port 8743. Now we can access the application using the public IP that the Fargate task provided. 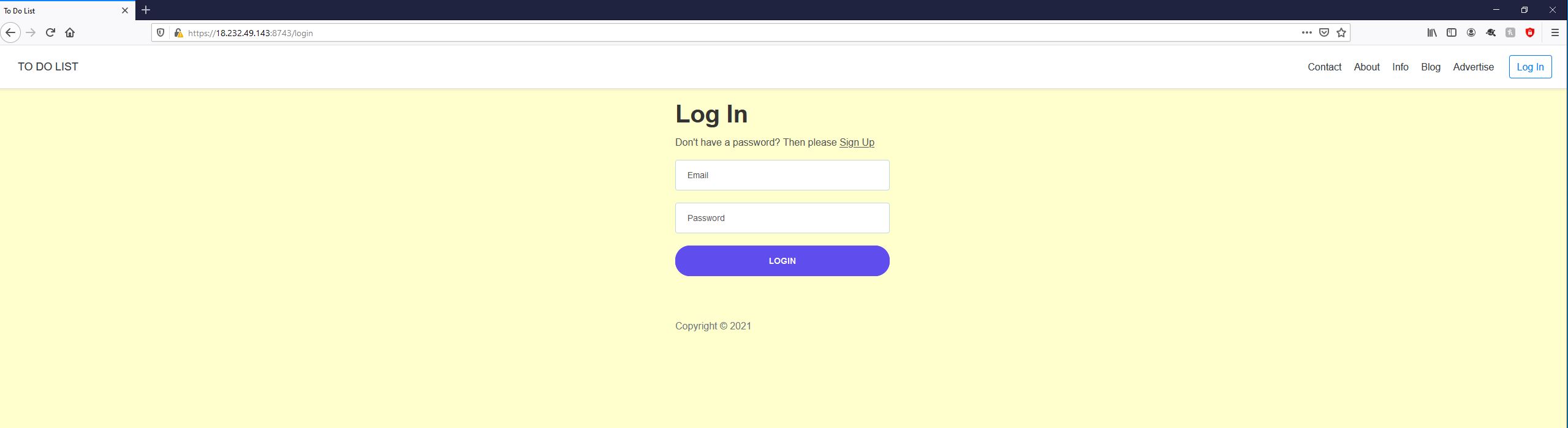 Here we go, we have our application up and running.
Here we go, we have our application up and running.