In this post, I plan to show an example of Spring Boot Application authentication with AWS Cognito. I will show two flows –
- OIDC Authentication
- SAML Authentication
AWS Cognito
AWS Cognito is a web service from AWS. Cognito is a user directory as well as an authentication mechanism service. In the enterprise industry, every application has two requirements from a user perspective.
- User Directory and Synchronization
- User Authentication
Cognito makes this easier by allowing the creation of a user pool or an identity pool. Once you have a pool, you can configure an application with the various settings for authentication. Another major advantage of Cognito is that it offers industry-standard security authentication protocols like OAuth 2.0, OpenID Connect, SAML.
There are equally other features like user access handling, but we won’t go into detail about that as part of this post. In this post, I will further show how we can create a user pool and configure an application to use that user pool.
Spring Boot Application
We will use a simple Spring Boot Application. We will integrate this application with AWS Cognito for authentication.
Spring Boot Setup
Add the following dependencies in the Gradle file
implementation 'org.springframework.boot:spring-boot-starter-security'
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.security:spring-security-oauth2-client'
implementation 'org.springframework.security:spring-security-oauth2-jose'
And the application.properties will need oauth2 configuration properties:
# ====================================================================================
## SSL Keystore for HTTPS
# ====================================================================================
#security.require-ssl=true
server.port=8743
server.ssl.key-store-password=******
server.ssl.key-store=classpath:sssstore.p12
server.ssl.key-store-type=PKCS12
server.ssl.key-alias=selfsigned_localhost
# =====================================================================================
spring.security.oauth2.client.registration.cognito.clientId=7mtivo8jobdtd6dvocldkmu6qk
spring.security.oauth2.client.registration.cognito.clientSecret=*********
spring.security.oauth2.client.registration.cognito.scope=openid
spring.security.oauth2.client.registration.cognito.redirect-uri=https://localhost:8743/login/oauth2/code/cognito
spring.security.oauth2.client.registration.cognito.clientName=SpringBootCognitoDemo
spring.security.oauth2.client.registration.cognito.authorization-grant-type=authorization_code
spring.security.oauth2.client.provider.cognito.issueUri=https://cognito-idp.{awszone}.amazonaws.com/{userPoolId}
spring.security.oauth2.client.provider.cognito.authorization-uri=https://{customDomain}.auth.{awszone}.amazoncognito.com/oauth2/authorize
spring.security.oauth2.client.provider.cognito.token-uri=https://{customDomain}.auth.{awszone}.amazoncognito.com/oauth2/token
spring.security.oauth2.client.provider.cognito.jwk-set-uri=https://cognito-idp.{awszone}.amazonaws.com/{userPoolId}/.well-known/jwks.json
spring.security.oauth2.client.provider.cognito.user-name-attribute= cognito:username
Security Configuration
Our Main Controller class will look like below:
@Controller
public class MainController
{
@GetMapping("/")
public String home(Model model, Principal principal)
{
model.addAttribute("username", principal.getName());
return "index";
}
}
So when we will access our application, it will redirect to AWS Cognito UI for authentication. Based on the selected flow OIDC or SAML, the authentication will happen.
SecurityConfig will be as below:
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter
{
@Autowired
public CustomLogoutSuccessHandler customLogoutSuccessHandler;
@Override
protected void configure(HttpSecurity httpSecurity) throws Exception
{
httpSecurity.csrf()
.and()
.authorizeRequests()
.anyRequest()
.authenticated()
.and()
.oauth2Login()
.and()
.logout()
.logoutUrl("/logout")
.logoutSuccessHandler(customLogoutSuccessHandler)
;
}
}
Our simple index template will look like below:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="utf-8">
<meta content="width=device-width, initial-scale=1" name="viewport">
<title>Cognito Demo</title>
</head>
<body>
<div class="container">
<h1 class="title">OAuth 2.0 Spring Security Cognito Demo</h1>
<div>
<div class="box">
Hello, <strong th:text="${username}"></strong>!
</div>
<a th:href="@{/logout}" class="btn btn-primary">Logout</a>
</div>
</div>
</body>
</html>
Create a User Pool
Once you log in to AWS Console, select Cognito as AWS Service. The first screen will show you two options – Create a user pool and Create an identity pool.
We will select Create a user pool.
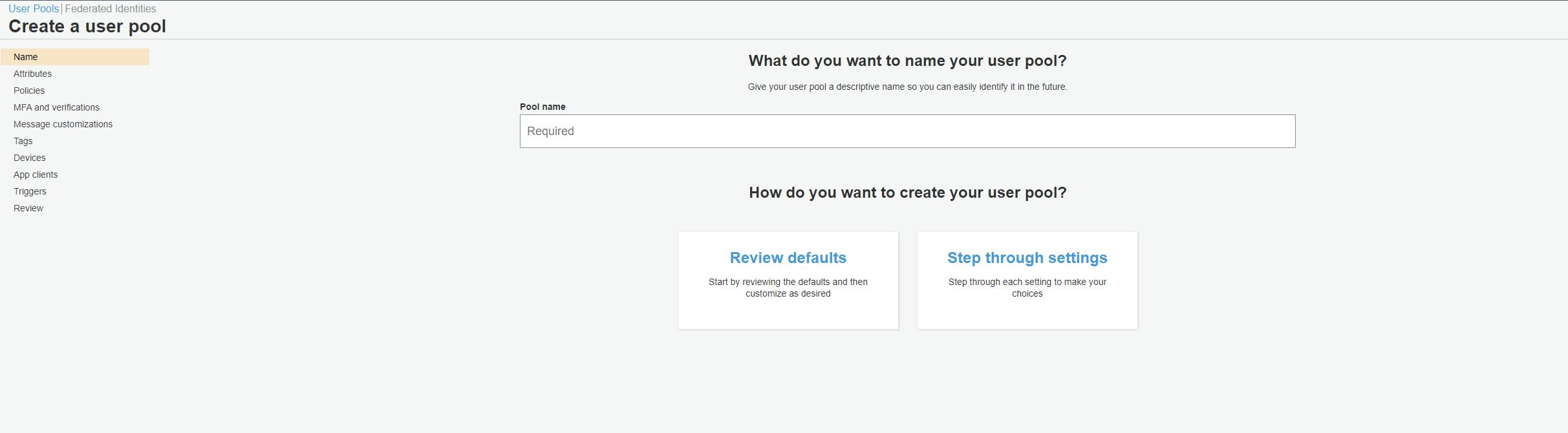
Enter a suitable name for your user pool and select Step through settings. This will allow us to modify any settings that we don’t want to use for our use case.
Now select user pool attributes for users. These attributes allow us to identify the user and what a user can enter during authentication.
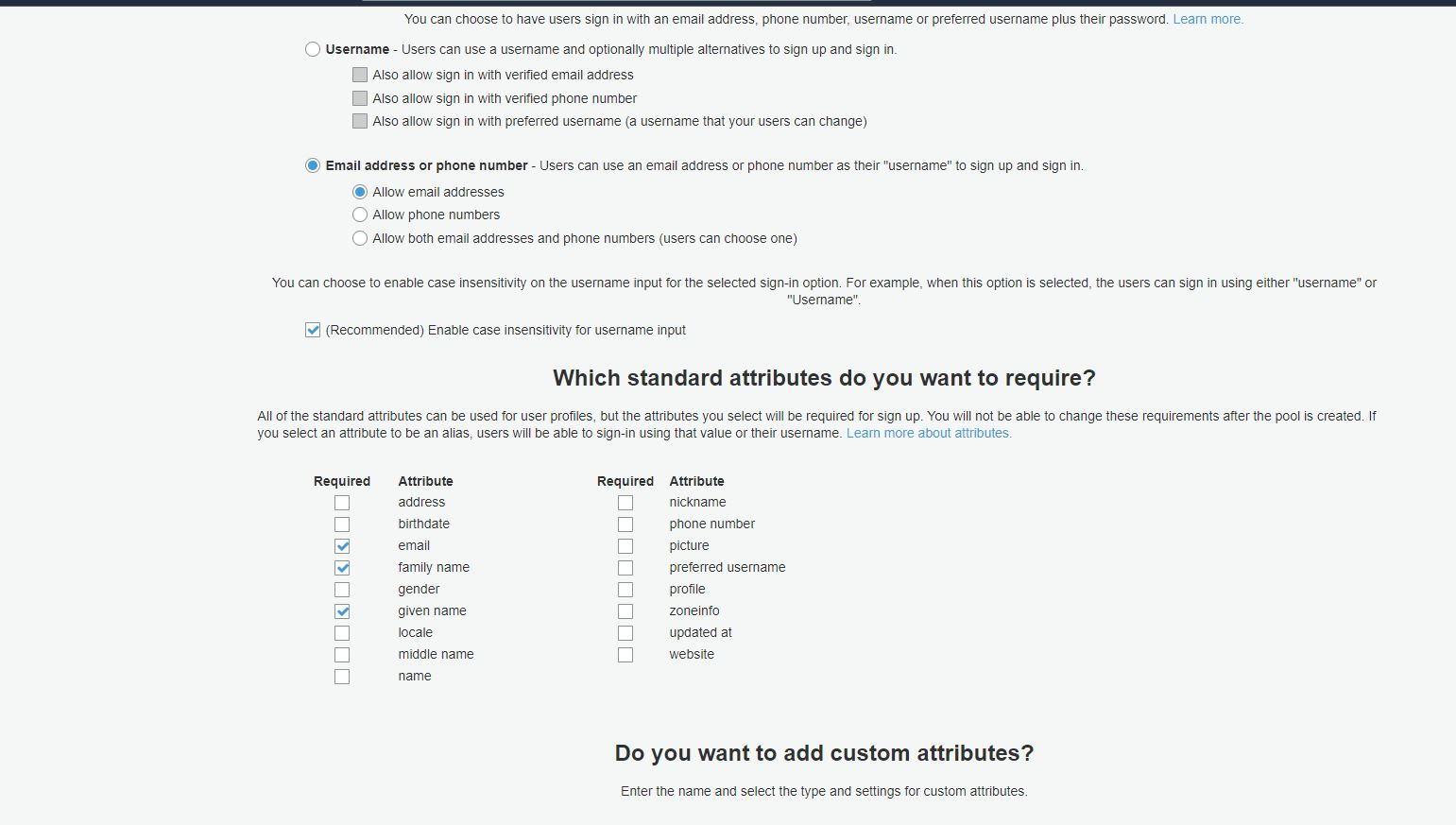
For our demo, we have selected Email address, family name, and given name as attributes. So the user will log in to the application using an email address.
For password policy, we have set that password should be of minimum length 8, should be alphanumeric with upper case and lower case characters.
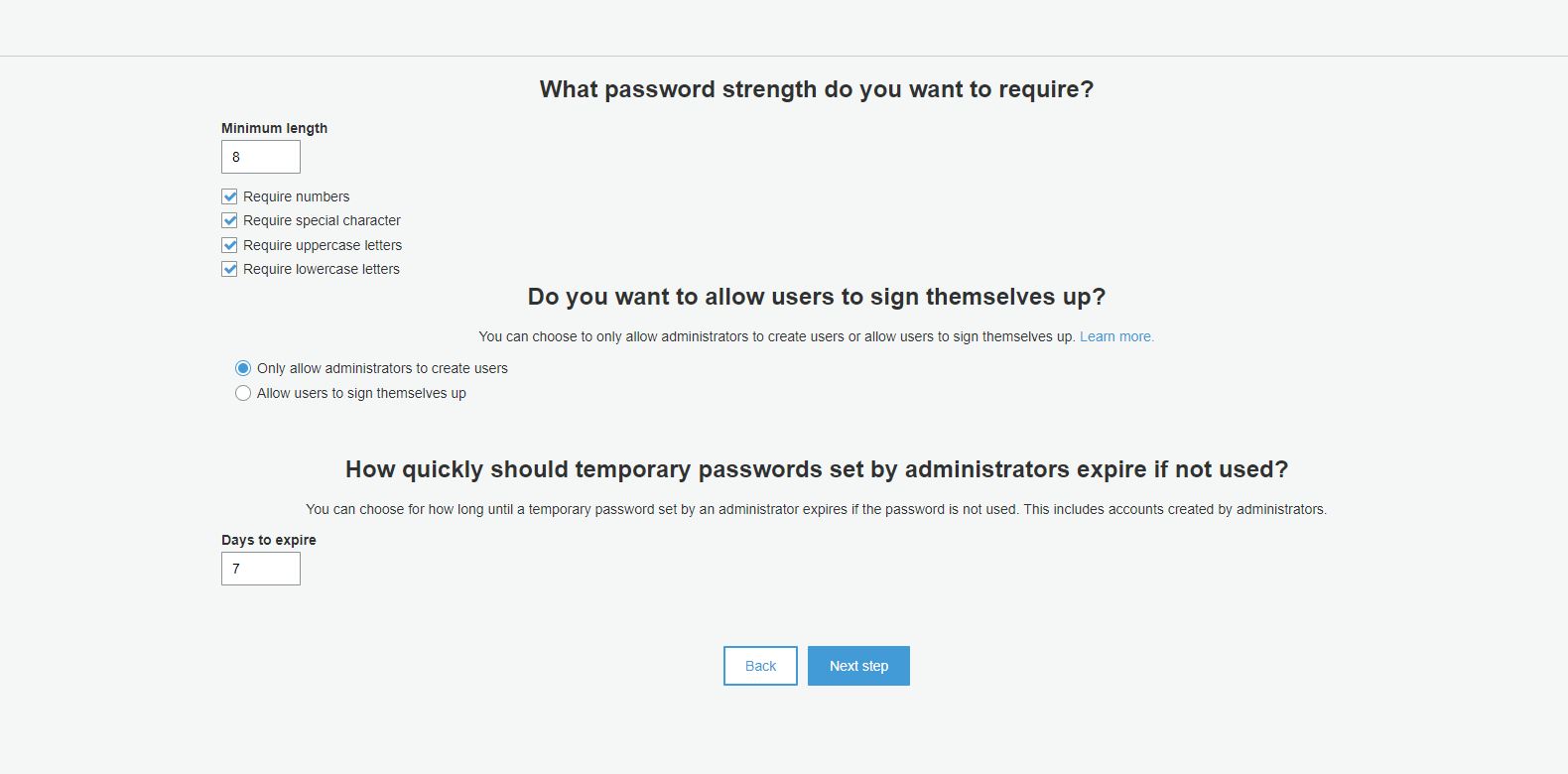
Most of the other settings we will choose as default. For App Clients Step, we will choose username and password-based authentication for Auth Flow.
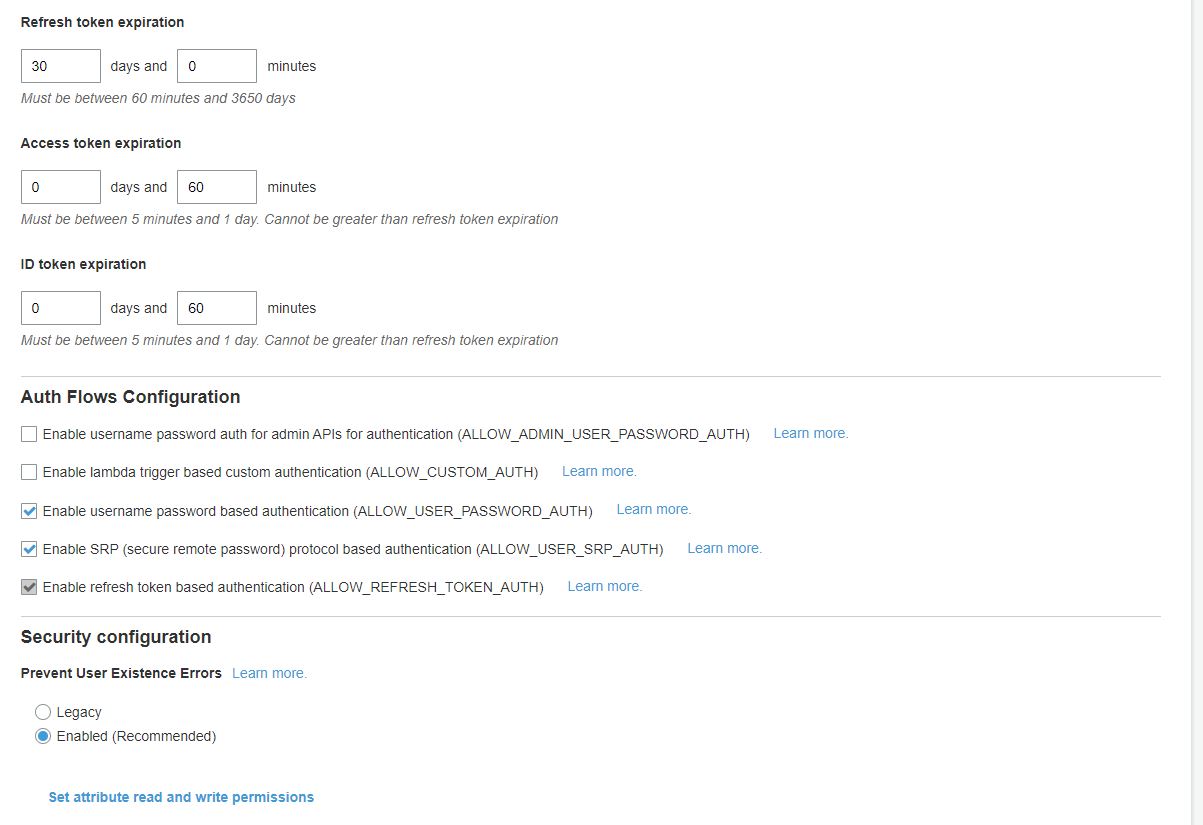
Application Client Configuration
Once we create a user pool, we will continue to step through the next set of configurations and that includes the Application Client. In this configuration, we configure our application that will be using the user pool.
We need to enable identity provider and Cognito User Pool.
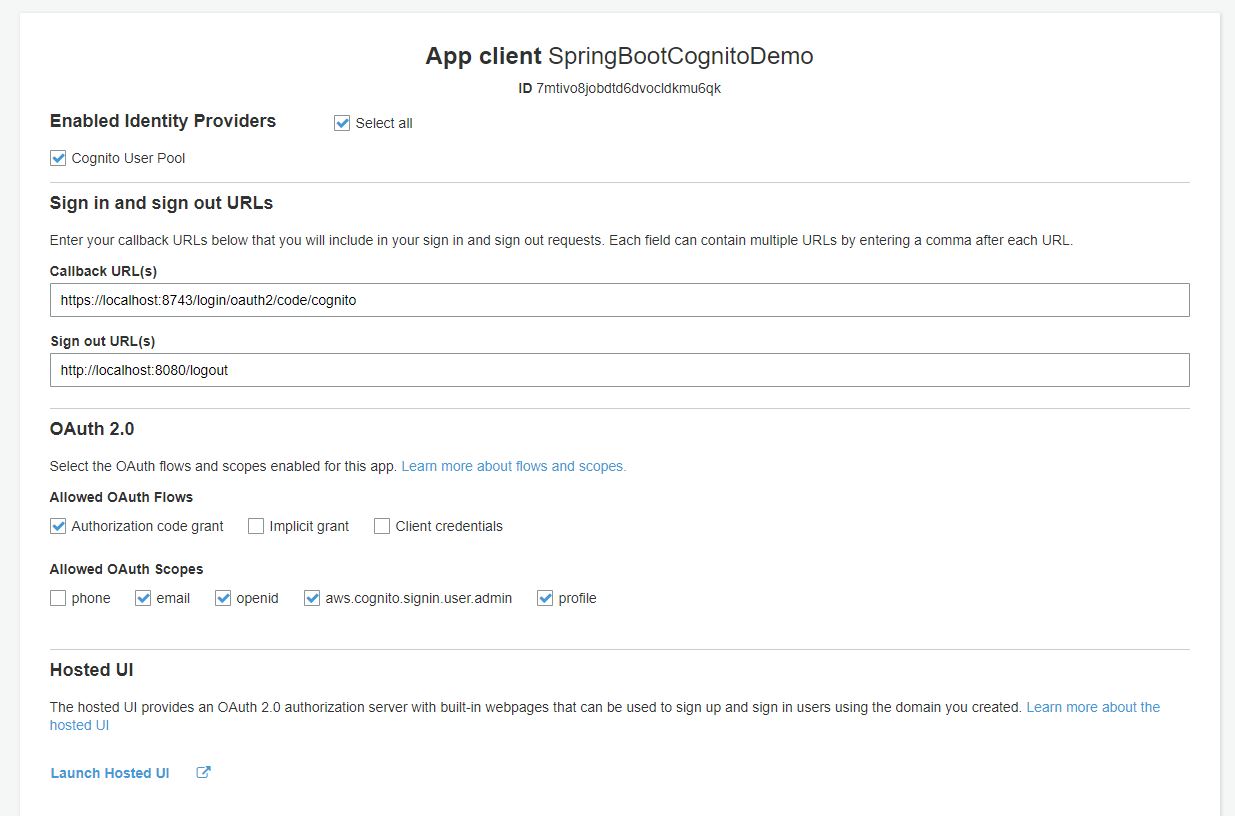
Configuring Federation Identity Provider
As mentioned previously, we will also configure a SAML Identity Provider for authentication. In this case, the flow will be application -> AWS Cognito -> SAML Identity Provider.
Configure Application in Okta
For this demo, we will use Okta as SAML Identity Provider. Log in to Okta Administrator console , configure a new application for SAML Integration as below:
On the next step, provide Single Sign On URL and this will be https://{yourcustomdomainfromcognito}.auth.{awszone}.amazoncognito.com. We also need to provide Audience URI (SP Entity ID). In this case, Cognito will act as Service Provider to Okta.
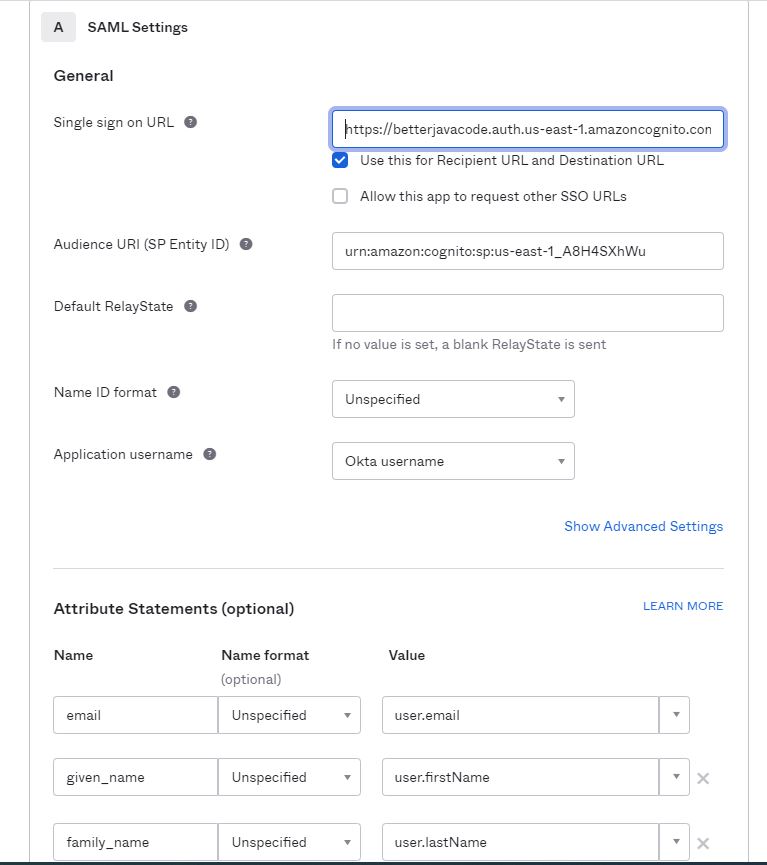
We also need to configure Attribute Statements as shown above. Those are the attributes we have configured in our Cognito User Attributes – email, given_name, family_name.
Basically, make sure that the user you plan to use is in Okta Users Directory. It will be the same user that we will need to be either configured in Cognito User Pool or created through sign-up.
Configure Federated Identity Provider in Cognito
- In our user pool configuration, select Federated Identity Provider.
- Choose the option of SAML and Cognito will show you to upload a metadata file or metadata URL for Identity Provider. In our case, it will be https://dev-19753289.okta.com/app/exkmt322q1Kl15Rsk5d6/sso/saml/metadata.
- Type a name for Federated Identity Provider and Save the changes.
Therefore, if we go back to App Client Settings, we should see an option to select Federated Identity Provider. With the new configuration, our settings will look like below:
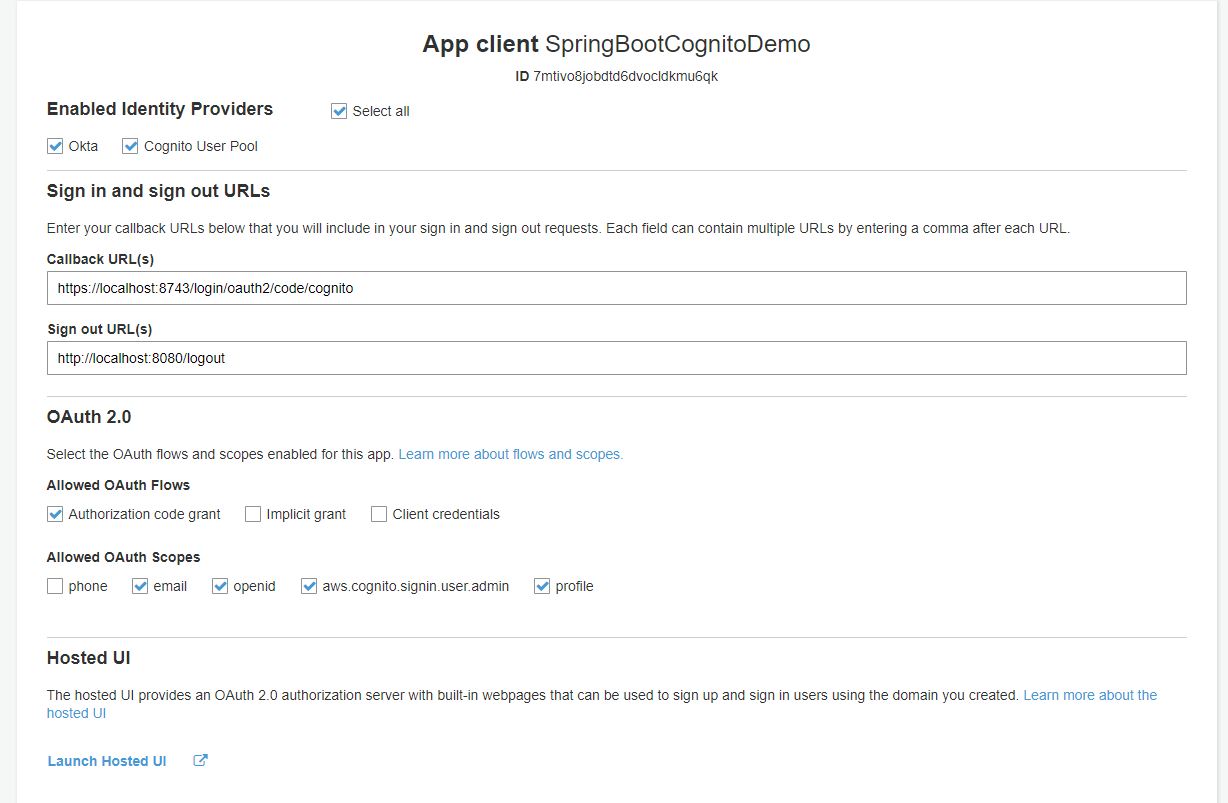
Anyhow, make sure the user attributes(given_name, family_name, and email) in Cognito are editable.
However, we have completed our configuration. Now we can show the demo.
Demo of Spring Boot Application Authentication with AWS Cognito
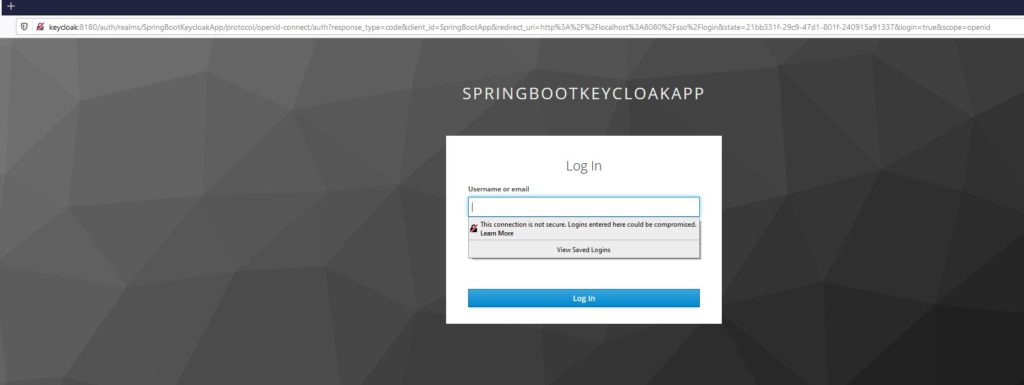
Now if I run my application and access it at https://localhost:8743/, I will see the following screen to select an identity provider to authenticate with:
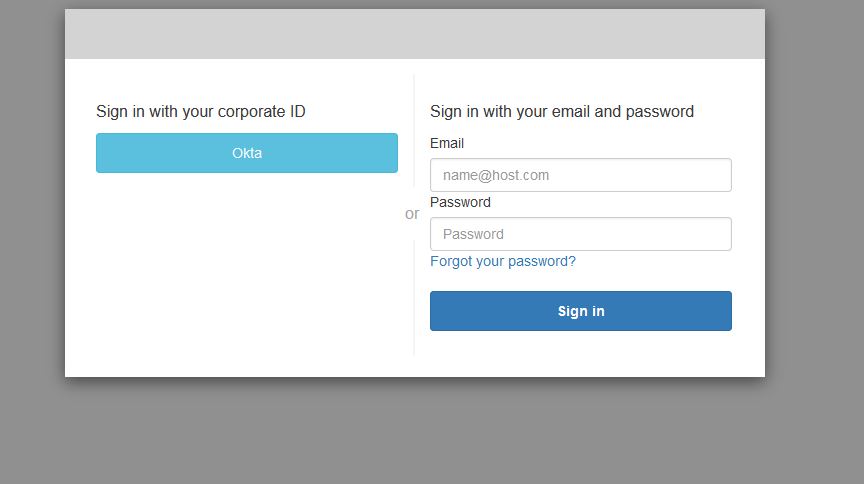
Nevertheless, we can use Okta or Cognito User Pool to log in.
SAML Flow
- User accesses the application that sends Authorization Code Flow OAuth request to Cognito
- Cognito sends SAML Request to Okta.
- The user enters credentials on the okta login screen.
- Okta sends the SAML response back to Cognito at endpoint
https://{customdomain}.auth.{awszone}.amazoncognito.com/saml2/idpresponse - Cognito processes the saml response and generates auth code and response back to the application.
- The application uses auth code to get token from Cognito and authenticates the user on verification of token.
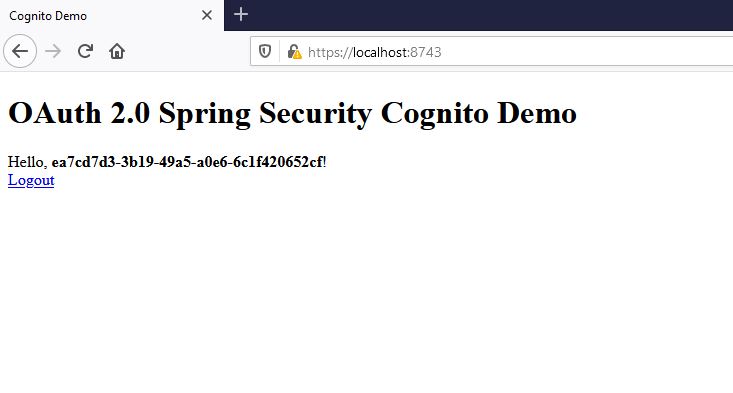
Above all, after successful authentication, the user will see
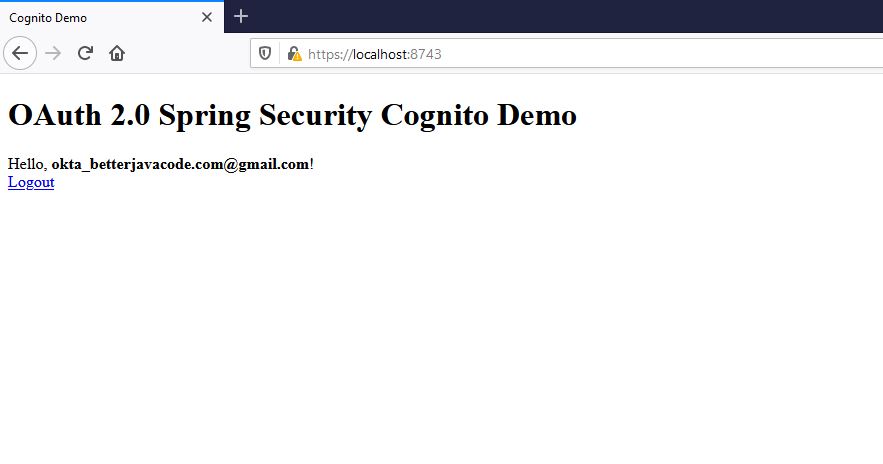
Instead of Okta, we had chosen Cognito login on the same Home Realm Discovery screen, we will see the following after successful authentication:
Conclusion
In this post, I showed how we can use AWS Cognito for authentication with Spring Boot application. Moreover, Cognito helps in configuring users as well as removing boilerplate code of security flows.
In conclusion, if you have not bought my ebook Simplifying Spring Security, it is available here.
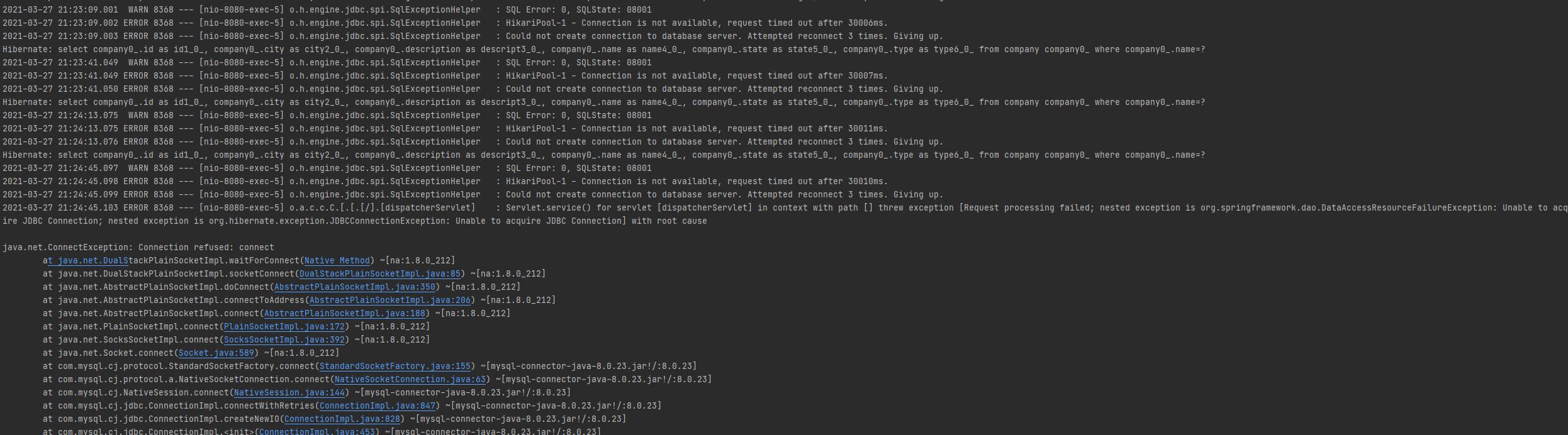
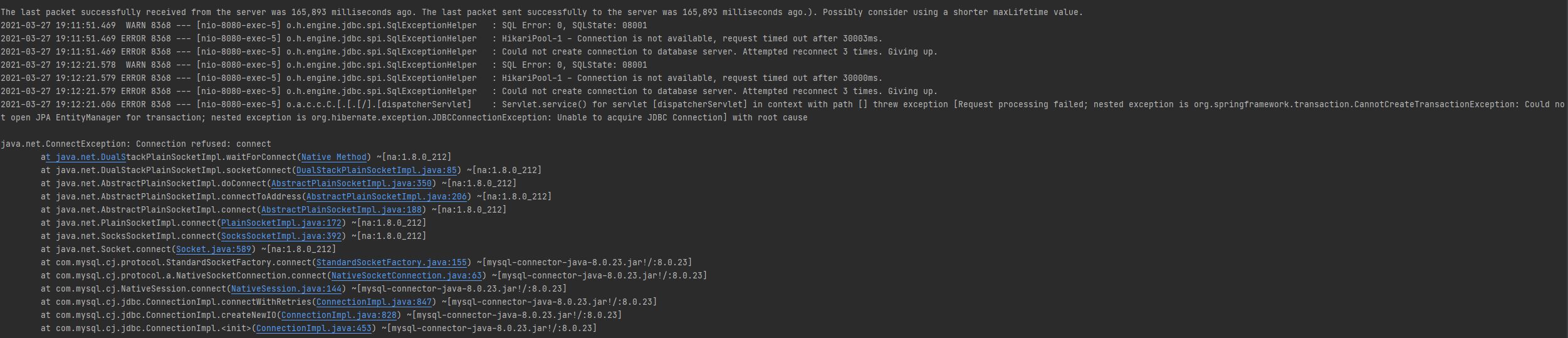 As you can see in the above screenshot, there were two attempts to retry. In each retry, it tried to connect to MySQL server thrice.
As you can see in the above screenshot, there were two attempts to retry. In each retry, it tried to connect to MySQL server thrice.