What makes a good Junior Developer? Yes, I will talk about some qualities every junior developer should develop to do better in this role. Now Junior Developer is a broad term, it can include Associate Software Engineers, Software Engineers, or Developers.
Once I was a Junior Developer too. Now I am in a senior role, but that doesn’t take away from me to still be a junior to other Seniors. So, I wish there was some kind of a guide to help junior developers to succeed in their roles.
Qualities that will help you succeed as a Junior Developer
- Be open-minded to take up a challenge – One quality I really appreciate about the junior developers that I have worked with so far is to take up a challenge. In the initial days, you want to learn as much as you can. Sometimes, it can be overwhelming, other times, it can be boring. But learn and read.
- Take ownership of the task you work on – If you get a task to work on, take ownership of that task till its completion. You can create trust with your peers by taking ownership of the task. If you get stuck with the task, ask questions about it to your seniors. Senior Developers are meant to help you.
- Ask questions – As a senior developer, I really appreciate developers who ask questions. Even if those questions can be easy to answer. If you are stuck or don’t know, ask the question. Even in meetings, if you ask a question, everybody should appreciate it. A question brings a different perspective. And every perspective matters.
- Help others – One way to build your career at any organization is by helping others as much as you can. So, help others. You solved a problem that many other developers are facing, share that knowledge. If you built an automation tool, share the tool. Other junior developers come to you, help them. Be so good that everyone comes to you.
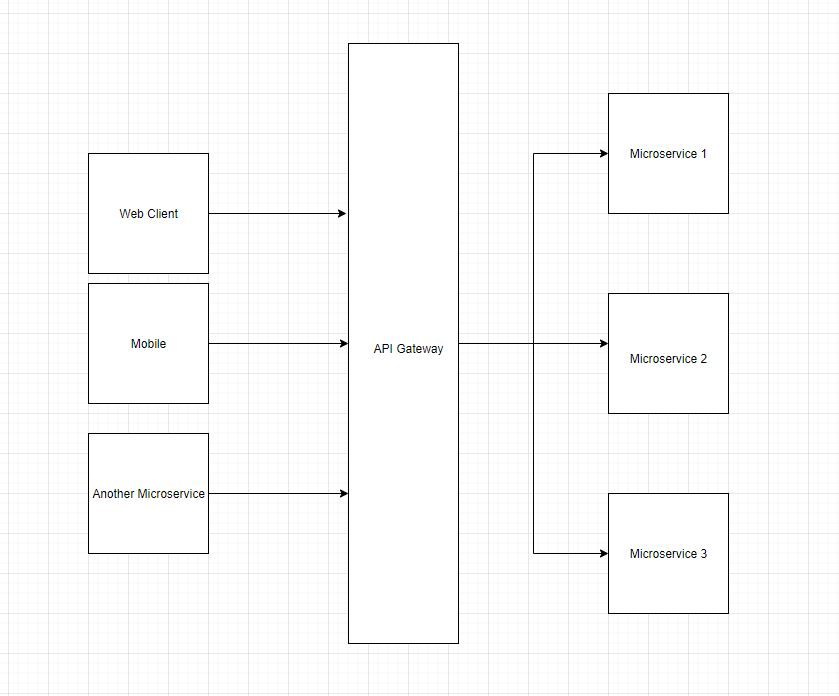
How to understand the system as a Junior Developer
Everyone has their own way to learn any skill or a complex system. But there are a few tried and tested ideas that can help you understand the system. This is definitely helpful in your initial days at any organization as a junior developer.
- Read and take notes. If there is documentation for the system architecture, read as much as you can. This will help you get the bigger picture of the system. If there is no documentation, then you are up against a challenge. Try to identify the components of the system that communicate with each other. Start creating documentation yourself so the future junior developers can thank you.
- Take up a task. Once you get a bigger picture, take up a task and work on it. Do a microanalysis of part of the system that you work on. Now this will provide you both a short distance view as well as a long-distance view of your system. Also, remember understanding any complex system takes time, so don’t be discouraged if you do not understand everything in a month or two.
- Read about system design in general. One way to build up your knowledge about any complex system is by reading about system design. Another way is to read the engineering blog of your company. A lot of passionate developers write these engineering blogs to share their knowledge worldwide.
Tips to succeed as a Junior Developer
- Read code – Read the code of the system you are working on. This will make you comfortable with code as well. Create your questions based on reading the code that you can ask senior developers.
- Participate in Code Review – One thing you will learn from code review to see how senior developers help in improving the code quality, so you can adapt to that quality. You will also learn to review others’ code.
- Write unit test cases – For whatever code you write, write unit test cases. This will set you apart from other developers.
- Start understanding where your team is struggling – Become a person who can identify a problem and find a solution. It’s very rare to find high-agency developers, but you can build up that skill. See where your team is struggling and how you can help the team in not struggling. Every team struggles with something. If as a Junior Developer, you have time, then help your team by building a tool or creating documentation of the system that has been ignored.
- Do not compare – Do not compare yourself with fellow junior or senior developers. Everyone’s path is different. So focus on what you can and can not do. Improve your skills.
- Ask for feedback – If there is no way to get feedback from a manager or senior developers, check in with your seniors once a month to get feedback. Feedback helps to improve. Find your own weaknesses and work on them.
Conclusion
In this post, I shared some tips and skills that a Junior Developer can use to be successful. If you enjoyed this post, comment on this post telling me what skill you think can make a Junior Developer stand out.
If you are still looking for my book Simplifying Spring Security, it is here to buy.