What is Spring Cloud? In this post, I will cover Spring Cloud Tutorial for beginners. If you are new to Spring Framework, I will suggest you start with Spring Boot and Microservices and Simplifying Spring Security.
As the official documentation on the Spring website says:
“Spring Cloud provides tools for developers to quickly build common patterns in distributed systems – configuration management, service discovery, circuit breakers, intelligent routing, microproxy, control bus, one-time tokens”

- What is Spring Cloud?
- Spring Cloud Features
- Spring Cloud Example in action
- Conclusion
What is Spring Cloud?
Spring Cloud provides readymade patterns to develop distributed system applications. Most of these patterns are common when building such applications.
One example is when there are multiple microservices and they interact with each other. You have to secure each service. Each service communicates with other services securely. Henceforth, how to secure these services? How do they communicate securely? And how do they get deployed seamlessly? What are the other automation tasks used for different requirements?
Using Spring Cloud, a developer can quickly build an application that implements these design patterns and deploy the application on cloud platforms( like Heroku or Cloud Foundry).
Spring Cloud Features
Spring framework is fundamental to building a Spring Cloud application. So what are the different features that Spring Cloud added?
Service Registration and Discovery
Spring Boot became popular with microservice architecture. When you have multiple services interacting with each other, you need a service to register each service, this is mostly Configuration Service. Then you need a discovery service to find other services.
Distributing Messaging
Basically, Spring cloud provides different tools to make our microservice-based architecture successful. Spring Boot helps rapid development of these applications. Spring Cloud assists in coordinating and deploying these applications. One such feature with Spring Cloud is distributed messaging.
Microservices communicate synchronously or asynchronously. Overall, Spring Cloud Bus offers a message broker that links nodes of a distributed system. Equally, Spring Cloud Stream offers a framework to build event-driven microservices. Nevertheless, this feature works well with messaging services like Kafka or ActiveMQ.
Service to Service Communication
Spring Cloud provides a feature for service-to-service communication. Usually, the flow goes like this
- Register the service
- Fetch the registry
- Find the target downstream service
- Call the REST endpoint of that service
Distributed Configuration
Particularly, the spring cloud config server allows externalized configuration on the client-side for the distributed systems.
Other than these features, Spring Cloud provides tools to build resilient and robust services. One such tool is circuit breakers.
As an illustration, we will create two microservices and one microservice will call another. We will use the feature of registry service (from Spring Cloud) to register these microservices.
Spring Cloud Example in Action
Build Eureka Server for Registry Service
First, we will create a service that will use the Eureka service and act as a registry service. As a result, add the following dependency in a new Spring Boot application:
plugins {
id 'org.springframework.boot' version '2.5.5'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
id 'java'
}
group = 'com.betterjavacode'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
repositories {
mavenCentral()
}
ext {
set('springCloudVersion', "2020.0.4")
}
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-server'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}"
}
}
test {
useJUnitPlatform()
}
Once we have that dependency, we can enable the eureka server in our main class.
package com.betterjavacode.eurekaserver;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaserverApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaserverApplication.class, args);
}
}
Add the following properties to application.yml
server:
port: 7000
# Discovery Server Access
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
The properties eureka.instance.client.register-with-eureka=false and eureka.instance.client.fetch-registry=false indicates that this is a registry server and won’t use itself to register.
A microservice to return products
In order to show how we will use the registry service as part of the entire Spring Cloud integration, we will create a new microservice. This REST-based microservice will return a list of products.
plugins {
id 'org.springframework.boot' version '2.5.5'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
id 'java'
}
group = 'com.betterjavacode'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
repositories {
mavenCentral()
}
ext {
set('springCloudVersion', "2020.0.4")
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}"
}
}
test {
useJUnitPlatform()
}
With this in mind, RESTController for this service will look like below:
package com.betterjavacode.productservice.controllers;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
@RestController
public class ProductController
{
@GetMapping("/products")
public List getAllProducts ()
{
List products = new ArrayList<>();
products.add("Shampoo");
products.add("Soap");
products.add("Cleaning Supplies");
products.add("Dishes");
return products;
}
}
And the application.yml file for this application will be like this
spring:
application:
name: product-service
server:
port: 8083
eureka:
client:
registerWithEureka: true
fetchRegistry: true
serviceUrl:
defaultZone: http://localhost:7000/eureka/
instance:
hostname: localhost
Here we have eureka.client.registerWithEureka=true and eureka.client.fetchRegistry=true as we want our service to be registered with our Eureka server running registry service. Subsequently, our main class for this service will have an annotation @EnableDiscoveryClient that will allow this service to be discovered by Eureka Server.
Client Service to call Product Service
Now, let’s create another service which will be a client service to product service. It will be very similar to Product Service except it will be based on MVC, so we will use a thymeleaf template to call this service.
package com.betterjavacode.productserviceclient.controllers;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.client.RestTemplate;
import java.util.List;
@Controller
public class ProductController
{
@Autowired
private DiscoveryClient discoveryClient;
@GetMapping("/")
public String home(Model model)
{
List serviceInstances = discoveryClient.getInstances("product" +
"-service");
if(serviceInstances != null && !serviceInstances.isEmpty())
{
ServiceInstance serviceInstance = serviceInstances.get(0);
String url = serviceInstance.getUri().toString();
url = url + "/products";
RestTemplate restTemplate = new RestTemplate();
List products = restTemplate.getForObject(url, List.class);
model.addAttribute("products", products);
}
return "home";
}
}
application.yml for this service will look like below:
spring:
application:
name: product-service-client
server:
port: 8084
eureka:
client:
registerWithEureka: true
fetchRegistry: true
serviceUrl:
defaultZone: http://localhost:7000/eureka/
instance:
hostname: localhost
Thymeleaf template for home will basically list the products in a table form.
Run the services
Shortly, run all the services – starting with Eureka server, product service and product-service-client. Now if we access eureka server, we will see the list of services registered with it as below:
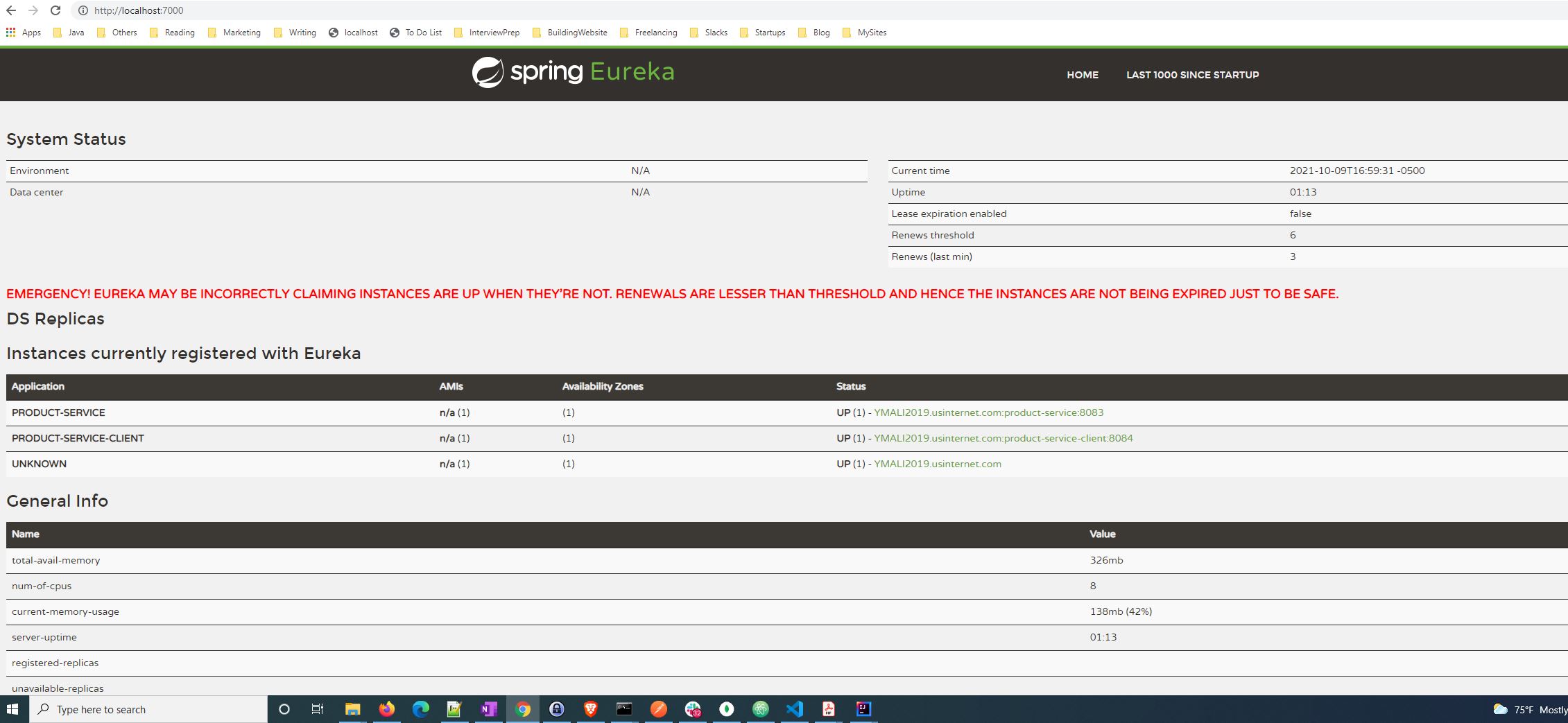
You can see both services registered. And if we access our product-service-client application at http://localhost:8084/, we will see the list of products
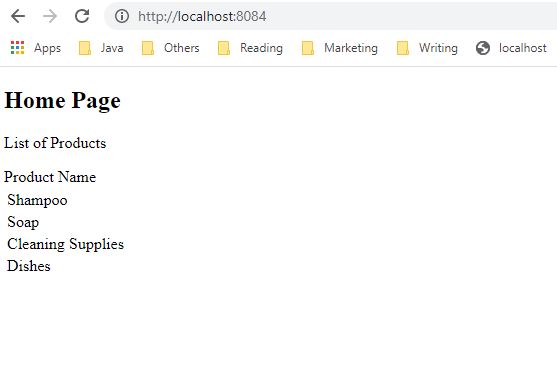
At last, we saw a simple demo of using Eureka server as a registry service with Spring Cloud. If you want to learn more about Spring Cloud Config, I definitely recommend this course Distributed configuration with Spring Cloud Config from udemy.
Conclusion
In this post, we learned about Spring Cloud. There are a number of features to evaluate in Spring Cloud. I have covered only a feature that most developers have to use while using Spring Cloud. A developer can also combine Spring Cloud Function with AWS Lambda to learn more about Spring Cloud.
If you are still looking to learn about Spring Security, you can my book here.
Note – Links for Udemy or Educative courses are affiliate links. If you end up buying those courses, I get a percentage of the total price. I also recommend only those courses that I have taken or have learned about that topic myself.