Logging is a key part of enterprise applications. Logging not only helps to investigate a problem but also helps to build relevant metrics. These metrics are important from a business perspective. In fact, businesses write service level agreements (SLA) using these metrics. In this post, we will talk about logging in Spring Boot-based Microservices.
If you are new to Spring Boot and Microservices, I will recommend reading about Spring Boot and Microservices.
Why do we log and what do we log?
The Production Level applications can fail anytime for various reasons. For a developer to investigate such issues in a timely manner, it becomes critical to have logs available. Logs are a key for applications to recover.
The question comes what do we log? Developers, software architects invest enough time to decide what to log. It’s equally important to not log a lot of information. You do not want to lose critical information. Evidently, one should not log any of PII (Personal Identifiable Information). A paradigm that developers can use is “What will help me to investigate issues in the code if the application fails?”. Especially, if a critical business decision needs comment in the code, it is an equally viable option to log that decision.
Concurrently, one can use a randomly generated trace id in the logs to trace the request-response. The harder part is to maintain this idea throughout the application’s life.
Logging and Observability
Microservices communicate with external APIs, other microservices. Henceforth, it is important to log the details of such communication. In event-driven microservices, one can log details of events. With cloud infrastructure, it has become easier to log details from microservices. Cloud infrastructure like AWS offers CloudWatch to collect these logs and then use the ELK stack to monitor the logs. However, observability tools like New Relic, Sumo Logic connect with different cloud infrastructures. They collect logs and offer flexibility to display, query, and build metrics based on logs.
Accordingly, developers have enough tools to log the data from applications to improve traceability and debugging.
Logging In Spring Boot Based Microservices
Let’s look at the logging in a Spring Boot-based Microservice. We will create a simple microservice and show what kind of logging configuration we can use.
Our main class looks like below:
package com.betterjavacode.loggingdemo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class LoggingdemoApplication {
public static void main(String[] args) {
SpringApplication.run(LoggingdemoApplication.class, args);
}
}
Basically, the microservice does not have anything at the moment. Regardless, we have a main class and we will see how the logging comes into the picture.
As part of the application, I have included a single dependency
implementation 'org.springframework.boot:spring-boot-starter-web'
This dependency also includes spring-boot-starter-logging . spring-boot-starter-logging is a default logging configuration that Spring Boot offers. We will look into more details.
Default Logging Configuration
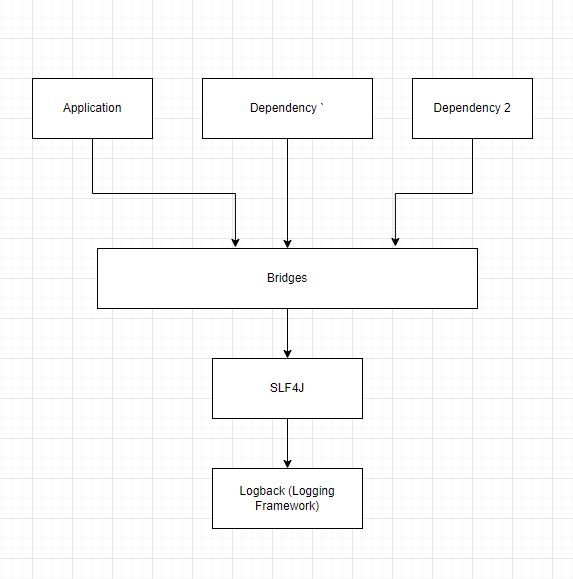
spring-boot-stater-logging dependency includes slf4j as a logging facade with logback as logging framework.
SLF4J is a logging facade that a number of frameworks support. The advantage of using this facade is that we can switch from one framework to another easily. Logback is the default framework in any spring boot application, but we can switch to Log4j, Log4J2, or Java Util Logging easily.
spring-boot-starter-logging includes the required bridges that take logs from other dependencies and delegate them to the logging framework.
Logback Logging Configuration
Analogous to what we added as a microservice and the default logging, we will see how we can use logback logging configuration. If we do not provide any configuration, spring boot will use the default configuration for logback. It will append the logs to console with the log level as info. Logging frameworks help us to propagate the logs to different targets like consoles, files, databases, or even Kafka.
With the configuration file (logback-spring.xml), we can also set the pattern of messages. If you want to use log4j2 instead logback, you can read this post about logging and error handling.
The following configuration file shows how we will be logging:
<configuration>
<property name="LOGDIRECTORY" value="./logs" />
<appender name="Console" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>
%black(%d{ISO8601}) %highlight(%-5level) [%blue(%t)] %yellow(%C{1.}): %msg%n%throwable
</Pattern>
</layout>
</appender>
<appender name="RollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOGDIRECTORY}/microservice.log</file>
<encoder
class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<Pattern>%d %p %C{1.} [%t] %m%n</Pattern>
</encoder>
<rollingPolicy
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOGDIRECTORY}/archived/microservice-%d{yyyy-MM-dd}.%i.log
</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>5MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
</appender>
<root level="info">
<appender-ref ref="RollingFile" />
<appender-ref ref="Console" />
</root>
<logger name="com.betterjavacode" level="debug" additivity="false">
<appender-ref ref="RollingFile" />
<appender-ref ref="Console" />
</logger>
</configuration>
We will dissect this file to understand what each line in the configuration does.
At first, we configured a property LOGDIRECTORY pointing to a physical directory on the machine where log files will be saved. We use this property in appender and rollingPolicy.
Different options for logging
Subsequently, we are using appender from Logback configuration to configure where we want to append our logs. In this case, we have configured for Console and File.
For ConsoleAppnder, we are using a pattern of messages that includes a date and time in black color, log level in blue, package in yellow color. The log message will be of the default color.
For RollingFileAppender, we have a line indicating what will be the file name and where it will be stored. In this case, we are logging in microservice.log in LOGDIRECTORY. The next line indicates the pattern for the log message.
%d– DateTime%p– log-level pattern%C– ClassName%t– thread%m– message%n– line separator
Thereafter, we define RollingPolicy. We want to make sure that we do not log the information in a single file and that keeps growing in size. We trigger the rolling out of the log file after it reaches a file size of 5 MB and save the old file in the archive directory with a name microservice-date-number.log.
Moving on, we will discuss the log level in the next section.
Configuring Log Level
The last part of the configuration file indicates log level. At the root level, we are logging everything at INFO level. Basically, our application will log all those messages that are written with INFO log level in the code.
But the next configuration allows us to set the log level at the package. In the package starting with com.betterjavacode, log all those messages that are on DEBUG level.
Executing the Spring Boot Application
Now, we will look at how this will be in our demo microservice.
I have a simple RestController in my application that retrieves company information as below:
package com.betterjavacode.loggingdemo.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
@RestController
@RequestMapping("/v1/companies")
public class CompanyController
{
private static final Logger LOGGER = LoggerFactory.getLogger(CompanyController.class);
@GetMapping
public List getAllCompanies()
{
LOGGER.debug("Getting all companies");
List result = new ArrayList<>();
result.add("Google");
result.add("Alphabet");
result.add("SpaceX");
LOGGER.debug("Got all companies - ", result);
return result;
}
}
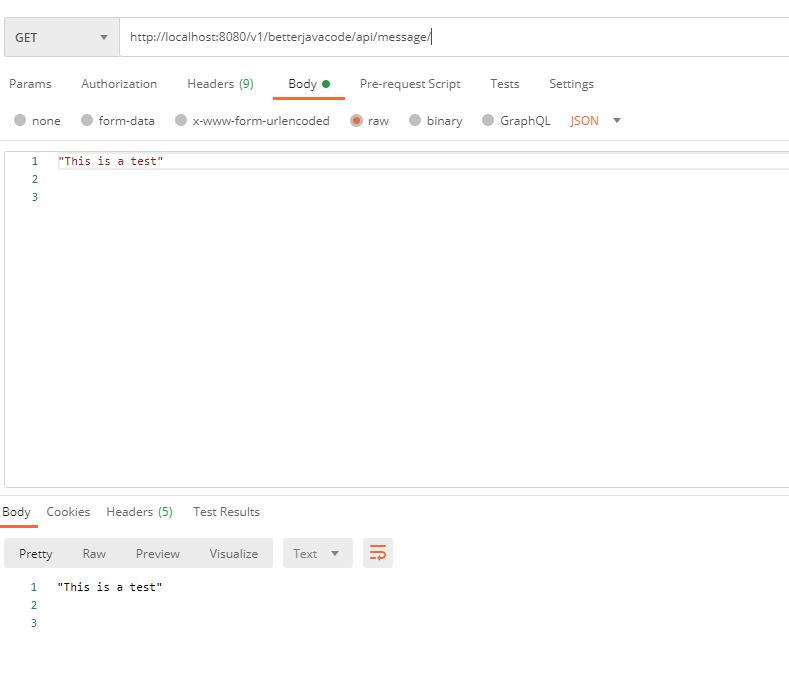
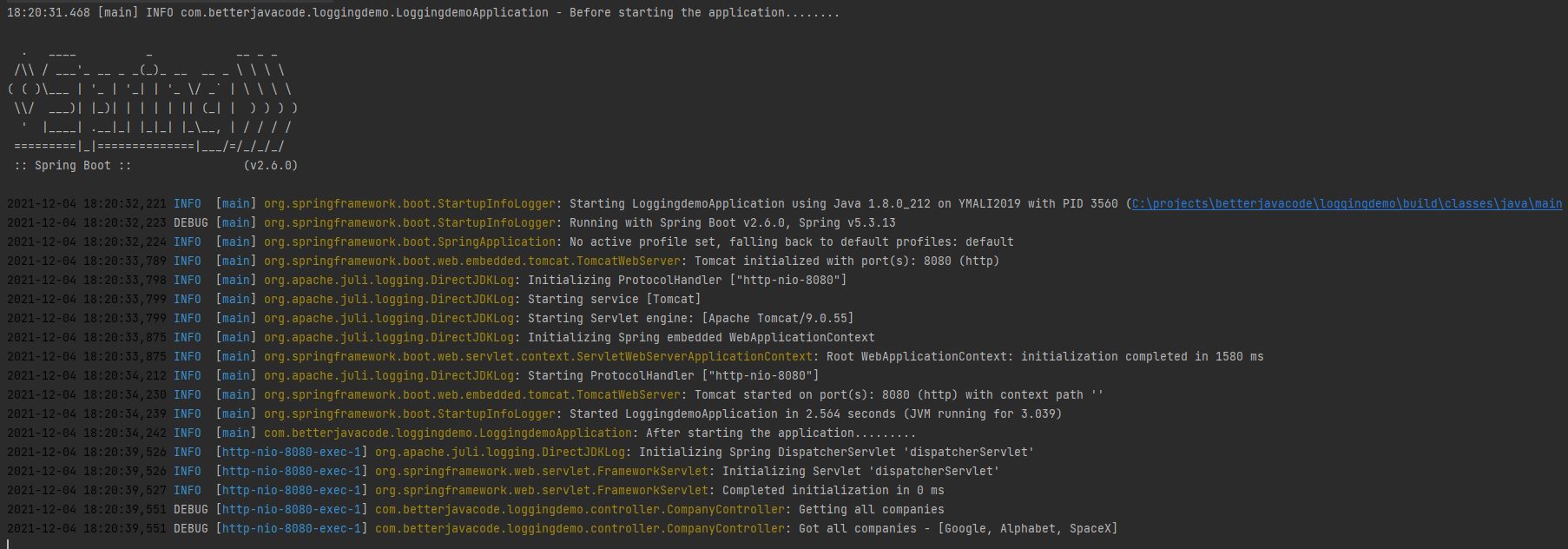
Now if execute our application and access the API http://localhost:8080/v1/companies/, we will get the list of companies, but also we will be able to view log on console as below:
The log file will look like below:
2021-12-04 18:20:32,221 INFO org.springframework.boot.StartupInfoLogger [main] Starting LoggingdemoApplication using Java 1.8.0_212 on YMALI2019 with PID 3560
2021-12-04 18:20:32,223 DEBUG org.springframework.boot.StartupInfoLogger [main] Running with Spring Boot v2.6.0, Spring v5.3.13
2021-12-04 18:20:32,224 INFO org.springframework.boot.SpringApplication [main] No active profile set, falling back to default profiles: default
2021-12-04 18:20:33,789 INFO org.springframework.boot.web.embedded.tomcat.TomcatWebServer [main] Tomcat initialized with port(s): 8080 (http)
2021-12-04 18:20:33,798 INFO org.apache.juli.logging.DirectJDKLog [main] Initializing ProtocolHandler ["http-nio-8080"]
2021-12-04 18:20:33,799 INFO org.apache.juli.logging.DirectJDKLog [main] Starting service [Tomcat]
2021-12-04 18:20:33,799 INFO org.apache.juli.logging.DirectJDKLog [main] Starting Servlet engine: [Apache Tomcat/9.0.55]
2021-12-04 18:20:33,875 INFO org.apache.juli.logging.DirectJDKLog [main] Initializing Spring embedded WebApplicationContext
2021-12-04 18:20:33,875 INFO org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext [main] Root WebApplicationContext: initialization completed in 1580 ms
2021-12-04 18:20:34,212 INFO org.apache.juli.logging.DirectJDKLog [main] Starting ProtocolHandler ["http-nio-8080"]
2021-12-04 18:20:34,230 INFO org.springframework.boot.web.embedded.tomcat.TomcatWebServer [main] Tomcat started on port(s): 8080 (http) with context path ''
2021-12-04 18:20:34,239 INFO org.springframework.boot.StartupInfoLogger [main] Started LoggingdemoApplication in 2.564 seconds (JVM running for 3.039)
2021-12-04 18:20:34,242 INFO com.betterjavacode.loggingdemo.LoggingdemoApplication [main] After starting the application.........
2021-12-04 18:20:39,526 INFO org.apache.juli.logging.DirectJDKLog [http-nio-8080-exec-1] Initializing Spring DispatcherServlet 'dispatcherServlet'
2021-12-04 18:20:39,526 INFO org.springframework.web.servlet.FrameworkServlet [http-nio-8080-exec-1] Initializing Servlet 'dispatcherServlet'
2021-12-04 18:20:39,527 INFO org.springframework.web.servlet.FrameworkServlet [http-nio-8080-exec-1] Completed initialization in 0 ms
2021-12-04 18:20:39,551 DEBUG com.betterjavacode.loggingdemo.controller.CompanyController [http-nio-8080-exec-1] Getting all companies
2021-12-04 18:20:39,551 DEBUG com.betterjavacode.loggingdemo.controller.CompanyController [http-nio-8080-exec-1] Got all companies - [Google, Alphabet, SpaceX]
Tracing the Requests
Previously, I stated why we log. When there are multiple microservices and each microservice is communicating with other and external APIs, it is important to have a way to trace the request. One of the ways is to configure a pattern in logback-spring.xml .
Another option is to use Filter and MDC (Mapping Diagnostic Context). Basically, each request coming to API will be intercepted through Filter. In Filter, you can add a unique id to MDC map. Use the logging pattern that uses the key from MDC map. This way, your request will have tracking information. One thing to remember is to clear the context from MDC once your API has responded to the client.
Configuring Logs for Monitoring
In the enterprise world, one way to configure logs is to store the logs in files and stash these files on a central location on a cloud server. AWS offers easier flexibility to pull this information in cloud watch from storage S3 and then one can use tools like Kibana and Elastic search for monitoring the logs and metrics.
Conclusion
In this post, we detailed how to use logging in spring boot-based microservices. We also discussed Logback configuration that one can use while using Logback framework in the Spring Boot application.
Most of these practices are standard and if followed properly, ensure the troubleshooting and monitoring of applications in a production environment.