In this post, I will discuss how the Spring Security Filter chain works. Spring Security uses a chain of filters to execute security features. If you want to customize or add your logic for any security feature, you can write your filter and call during the chain execution.
Introduction
If you use Spring security in a web application, the request from the client will go through a chain of security filters. Security filters adapt this concept from Web Servlets.
Basically, you have a controller to receive user requests. Security filters will intercept the incoming request and perform validation for authentication or authorization before redirecting the request to the target controller.
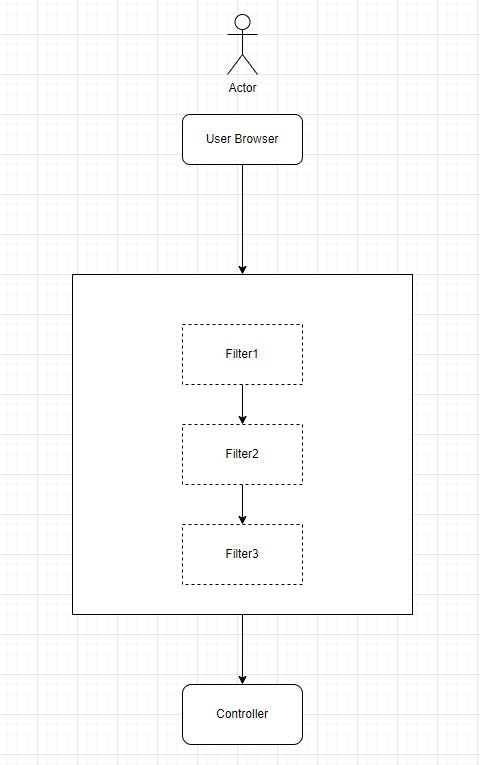
In short, the flow goes like
- The user accesses the application that is secured through Spring Security. Usually, this will be through a web browser and the application will send the request to a web server.
- The web server parses the incoming request
HttpServletRequestand passes it through Spring Security filters. Each filter will perform its logic to make sure the incoming request is secure. - If everything goes well, the request will eventually come to MVC Controller which hosts the backend for the application. Filters can create
HttpServletResponseand return to the client without even reaching the controller.
What is Spring Security Filter Chain?
Let’s create a simple web app using Spring Boot and Spring Security.
Add these two dependencies in your build.gradle file to get started
implementation 'org.springframework.boot:spring-boot-starter-security'
implementation 'org.springframework.boot:spring-boot-starter-web'
Controller
I will keep this app simple, so let’s add a REST controller to our web app.
package com.betterjavacode.securityfilterdemo.controllers;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class MainController
{
@GetMapping("/home")
public String home() {
return "Welcome, home!!!!";
}
}
Consequently, we will run our application now.
Run the application
Once, we execute the app, we will see the log that Spring Boot prints by default. This log looks like the below:
2022-08-13 10:24:13.120 INFO 9368 --- [ main] c.b.s.SecurityfilterdemoApplication : Starting SecurityfilterdemoApplication using Java 1.8.0_212 on YMALI2019 with PID 9368 (C:\projects\securityfilterdemo\build\libs\securityfilterdemo-0.0.1-SNAPSHOT.jar started by Yogesh Mali in C:\projects\securityfilterdemo\build\libs)
2022-08-13 10:24:13.123 INFO 9368 --- [ main] c.b.s.SecurityfilterdemoApplication : No active profile set, falling back to 1 default profile: "default"
2022-08-13 10:24:14.543 INFO 9368 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
2022-08-13 10:24:14.553 INFO 9368 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2022-08-13 10:24:14.553 INFO 9368 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.65]
2022-08-13 10:24:14.619 INFO 9368 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2022-08-13 10:24:14.619 INFO 9368 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 1433 ms
2022-08-13 10:24:14.970 WARN 9368 --- [ main] .s.s.UserDetailsServiceAutoConfiguration :
Using generated security password: 22bd9a92-2130-487c-bf59-71e61c8124ee
This generated password is for development use only. Your security configuration must be updated before running your application in production.
2022-08-13 10:24:15.069 INFO 9368 --- [ main] o.s.s.web.DefaultSecurityFilterChain : Will secure any request with [org.springframework.security.web.session.DisableEncodeUrlFilter@22555ebf, org.springframework.security.web.context.request.async.WebAsyncManagerIntegrationFilter@36ebc363, org.springframework.security.web.context.SecurityContextPersistenceFilter@34123d65, org.springframework.security.web.header.HeaderWriterFilter@73a1e9a9, org.springframework.security.web.csrf.CsrfFilter@1aafa419, org.springframework.security.web.authentication.logout.LogoutFilter@515c6049, org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter@408d971b, org.springframework.security.web.authentication.ui.DefaultLoginPageGeneratingFilter@41d477ed, org.springframework.security.web.authentication.ui.DefaultLogoutPageGeneratingFilter@45752059, org.springframework.security.web.authentication.www.BasicAuthenticationFilter@c730b35, org.springframework.security.web.savedrequest.RequestCacheAwareFilter@65fb9ffc, org.springframework.security.web.servletapi.SecurityContextHolderAwareRequestFilter@1bb5a082, org.springframework.security.web.authentication.AnonymousAuthenticationFilter@34e9fd99, org.springframework.security.web.session.SessionManagementFilter@7b98f307, org.springframework.security.web.access.ExceptionTranslationFilter@14cd1699, org.springframework.security.web.access.intercept.FilterSecurityInterceptor@1d296da]
2022-08-13 10:24:15.127 INFO 9368 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2022-08-13 10:24:15.138 INFO 9368 --- [ main] c.b.s.SecurityfilterdemoApplication : Started SecurityfilterdemoApplication in 2.477 seconds (JVM running for 2.856)
We can see the spring security-generated password. But there is also a log message
Will secure any request with [org.springframework.security.web.session.DisableEncodeUrlFilter@22555ebf,
org.springframework.security.web.context.request.async.WebAsyncManagerIntegrationFilter@36ebc363,
org.springframework.security.web.context.SecurityContextPersistenceFilter@34123d65,
org.springframework.security.web.header.HeaderWriterFilter@73a1e9a9,
org.springframework.security.web.csrf.CsrfFilter@1aafa419,
org.springframework.security.web.authentication.logout.LogoutFilter@515c6049,
org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter@408d971b,
org.springframework.security.web.authentication.ui.DefaultLoginPageGeneratingFilter@41d477ed,
org.springframework.security.web.authentication.ui.DefaultLogoutPageGeneratingFilter@45752059,
org.springframework.security.web.authentication.www.BasicAuthenticationFilter@c730b35,
org.springframework.security.web.savedrequest.RequestCacheAwareFilter@65fb9ffc,
org.springframework.security.web.servletapi.SecurityContextHolderAwareRequestFilter@1bb5a082,
org.springframework.security.web.authentication.AnonymousAuthenticationFilter@34e9fd99,
org.springframework.security.web.session.SessionManagementFilter@7b98f307,
org.springframework.security.web.access.ExceptionTranslationFilter@14cd1699,
org.springframework.security.web.access.intercept.FilterSecurityInterceptor@1d296da]
The above list shows the number of filters in the chain of security filters. Spring Security automatically configures these filters on every incoming request. Filters are executed in that specific order. One can change the order by the configuration of modules.
Security Filters
Now, we have covered the basics of Spring Security Filters. Let’s look at how these filters are stacked with Servlet filters and Spring’s application context.
DelegatingFilterProxy is the filter that acts as a bridge between the Servlet container’s life cycle and Spring’s application context. Once the initial request comes to DelegatingFilterProxy filter, it delegates the request to Spring Bean to start the security filter flow.
FilterChainProxy is the filter that contains information about all the security filters. It matches the incoming request with URI mapping and accordingly passes the request to that filter. DelegatingFilterProxy start the security flow by calling FilterChainProxy.
FilterChainProxy determines which SecurityFilterChain to call from the incoming request. One can implement RequestMatcher interface to create rules for your security filter chain.
As shown above, Spring Security contains different security filters, but there are certain filters that are critical when the incoming request passes through them.
UsernamePasswordAuthenticationFilter – If your application is configured for Username and Password, the request will pass through this filter to process username/password authentication.
SecurityContextPersistenceFilter – Once the user is authenticated, the user information is configured in a security context. This filter populates SecurityContextHolder.
Conclusion
In this post, I showed the details of the Spring Security Filter Chain and how it works. Once you understand these fundamentals, it becomes easier to configure and customize Spring Security for your web application.
If you want to read more about Spring Security and how to use it for SAML, and OAuth flows, you can buy my book Simplifying Spring Security.