In this post, I will show how to use a custom protocol mapper with Keycloak. In my previous post, I showed how to use keycloak as an identity-broker. This post focuses on how to use Keycloak for retrieving custom attributes during authentication.
Keycloak offers basic attributes like sub, iss in the access token or id token it generates. If we need some organization-specific or user-specific attributes, we can configure a custom protocol mapper in Keycloak.
Our client application will receive a token that will have attributes from our custom mapper.
Configure Keycloak for Client
Let’s configure a client in Keycloak for OIDC Protocol.
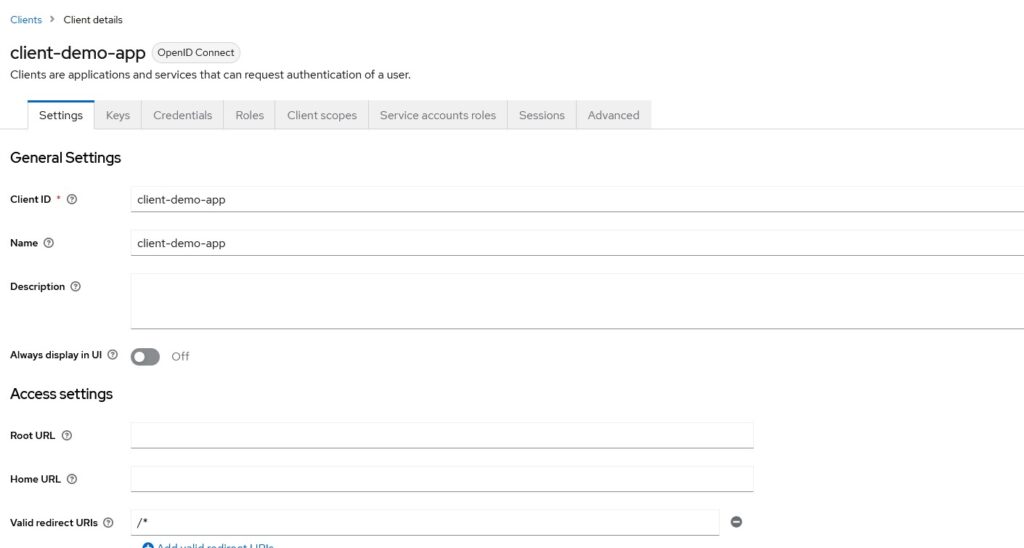
I have left Root URL, Home URL and Valid Redirect URIs almost empty. When you will have an actual application, you will need to provide a valid redirect URI that Keycloak will redirect to. Your application should handle the response from Keycloak on that URL.
You can configure what flows you will be supporting for OAuth
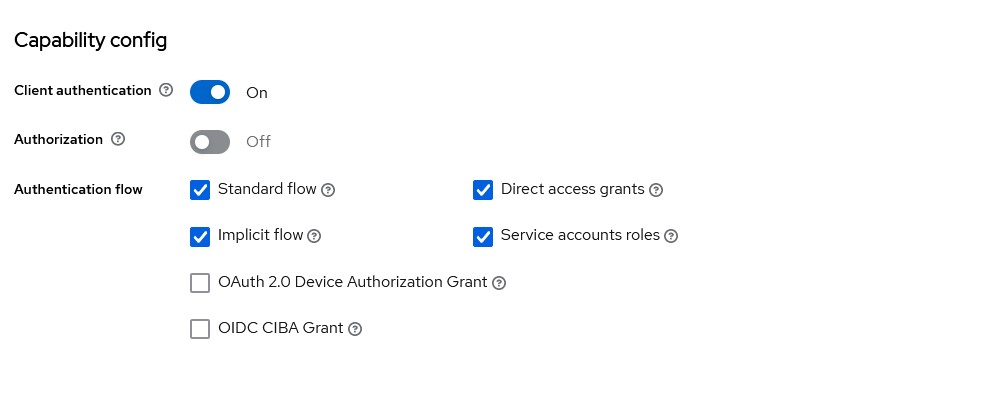
We leave the rest of the configuration as is for now and revisit when we have out custom mapper ready.
Default Protocol Mapper
If you run the Keycloak and use the client app that we created previously, we should be able to get Access Token and Id Token. That will provide us with default attributes in the token like below:
{
"exp": 1691786636,
"iat": 1691786576,
"jti": "8c75305a-54fd-4ab3-a936-ef7ebd5b4a71",
"iss": "http://keycloak:8180/realms/master",
"aud": "account",
"sub": "909ae4f5-e296-4c83-a18d-1406584ea43d",
"typ": "Bearer",
"azp": "client-demo-app",
"acr": "1",
"allowed-origins": [
"/*"
],
"realm_access": {
"roles": [
"default-roles-master",
"offline_access",
"uma_authorization"
]
},
"scope": "openid email offline_access profile",
"clientId": "client-demo-app"
}
As you see in this token, most claims are standard claims that Keycloak provides. For our user, we have not configured email or any other profile attributes, otherwise, Keycloak will provide that too.
Implementing Custom Protocol Mapper
The major advantage of Keycloak is that it allows developers to write different types of extensions. One such extension is Protocol Mapper.
Dependencies
Let’s create a Maven project and add the following dependencies.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.betterjavacode</groupId>
<artifactId>customKeycloakProtocolMapper</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<keycloak.version>21.0.0</keycloak.version>
</properties>
<dependencies>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-core</artifactId>
<version>${keycloak.version}</version>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-server-spi</artifactId>
<version>${keycloak.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-server-spi-private</artifactId>
<version>${keycloak.version}</version>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-services</artifactId>
<version>${keycloak.version}</version>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-saml-core</artifactId>
<version>${keycloak.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-saml-adapter-core</artifactId>
<version>${keycloak.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-saml-adapter-api-public</artifactId>
<version>${keycloak.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-saml-core-public</artifactId>
<version>${keycloak.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<excludes>
<exclude>**/*LiveTest.java</exclude>
</excludes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>6</source>
<target>6</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
Implementing Custom Protocol Mapper
In our Maven project, we will create a new class CustomOIDCProtocolMapper. This class will implement few interfaces OIDCAccessTokenMapper, OIDCIdTokenMapper and UserInfoTokenMapper. This class will also extend an abstract class AbstractOIDCProtocolMapper.
package com.betterjavacode;
import org.keycloak.models.ClientSessionContext;
import org.keycloak.models.KeycloakSession;
import org.keycloak.models.ProtocolMapperModel;
import org.keycloak.models.UserSessionModel;
import org.keycloak.protocol.ProtocolMapperUtils;
import org.keycloak.protocol.oidc.OIDCLoginProtocol;
import org.keycloak.protocol.oidc.mappers.*;
import org.keycloak.provider.ProviderConfigProperty;
import org.keycloak.representations.AccessToken;
import org.keycloak.representations.IDToken;
import java.util.*;
/**
* Handle Custom Claims for OIDC Protocol
*/
public class CustomOIDCProtocolMapper extends AbstractOIDCProtocolMapper
implements OIDCAccessTokenMapper, OIDCIDTokenMapper, UserInfoTokenMapper
{
public static final String PROVIDER_ID = "oidc-customprotocolmapper";
private static final List configProperties = new ArrayList();
static {
ProviderConfigProperty property;
property = new ProviderConfigProperty();
property.setName(ProtocolMapperUtils.USER_ATTRIBUTE);
property.setLabel(ProtocolMapperUtils.USER_MODEL_ATTRIBUTE_LABEL);
property.setHelpText(ProtocolMapperUtils.USER_MODEL_ATTRIBUTE_HELP_TEXT);
property.setType(ProviderConfigProperty.STRING_TYPE);
configProperties.add(property);
property = new ProviderConfigProperty();
property.setName(ProtocolMapperUtils.MULTIVALUED);
property.setLabel(ProtocolMapperUtils.MULTIVALUED_LABEL);
property.setHelpText(ProtocolMapperUtils.MULTIVALUED_HELP_TEXT);
property.setType(ProviderConfigProperty.BOOLEAN_TYPE);
configProperties.add(property);
OIDCAttributeMapperHelper.addTokenClaimNameConfig(configProperties);
OIDCAttributeMapperHelper.addIncludeInTokensConfig(configProperties, CustomOIDCProtocolMapper.class);
}
@Override
public String getDisplayCategory ()
{
return TOKEN_MAPPER_CATEGORY;
}
@Override
public String getDisplayType ()
{
return "Custom Claim Mapper";
}
@Override
public String getHelpText ()
{
return "Custom OIDC Protocol Mapper";
}
@Override
public List getConfigProperties ()
{
return configProperties;
}
@Override
public String getId ()
{
return PROVIDER_ID;
}
@Override
public List getConfigMetadata ()
{
return super.getConfigMetadata();
}
@Override
protected void setClaim(IDToken token, ProtocolMapperModel mappingModel, UserSessionModel userSession,
KeycloakSession keycloakSession, ClientSessionContext clientSessionCtx) {
OIDCAttributeMapperHelper.mapClaim(token, mappingModel, "SimpleTextAttributeValue");
}
public IDToken transformIDToken(IDToken token, ProtocolMapperModel mappingModel,
KeycloakSession session, UserSessionModel userSession,
ClientSessionContext clientSessionCtx) {
token.getOtherClaims().put("given_name", userSession.getUser().getFirstName());
token.getOtherClaims().put("family_name", userSession.getUser().getLastName());
token.getOtherClaims().put("email", userSession.getUser().getEmail());
token.getOtherClaims().put("name", userSession.getUser().getUsername());
setClaim(token, mappingModel, userSession, session, clientSessionCtx);
return token;
}
public AccessToken transformAccessToken(AccessToken token, ProtocolMapperModel mappingModel, KeycloakSession keycloakSession,
UserSessionModel userSession, ClientSessionContext clientSessionCtx) {
token.getOtherClaims().put("name", userSession.getUser().getUsername());
setClaim(token, mappingModel, userSession, keycloakSession, clientSessionCtx);
return token;
}
public static ProtocolMapperModel create(String name,
boolean accessToken, boolean idToken, boolean userInfo) {
ProtocolMapperModel mapper = new ProtocolMapperModel();
mapper.setName(name);
mapper.setProtocolMapper(PROVIDER_ID);
mapper.setProtocol(OIDCLoginProtocol.LOGIN_PROTOCOL);
Map<String, String> config = new HashMap<String, String>();
config.put(OIDCAttributeMapperHelper.INCLUDE_IN_ACCESS_TOKEN, "true");
config.put(OIDCAttributeMapperHelper.INCLUDE_IN_ID_TOKEN, "true");
mapper.setConfig(config);
return mapper;
}
}
In the above code, there are a couple of important methods to look at
setClaims – it adds custom data to token. SimpleTextAttributeValue will be part of the token once we set up that claim.transformAccessToken and transformIdToken – We can also add additional user attributes to the default Access Token and Id Token. In many cases, you don’t want to expose a lot of user data in Access Token.- Other methods like
getDisplayType and getHelpText are helper methods for Keycloak admin console.
Building a jar for Protocol Mapper
Before we can use this custom protocol mapper in our Keycloak configuration, we will need to build our maven project. To be able to use this mapper, we need to add a file with the name org.keycloak.protocol.ProtocolMapper in resources/META-INF/services directory.
Add the following value to this file –
com.betterjavacode.CustomOIDCProtocolMapper
This is our class for custom mapper. Our Keycloak configuration then will be able to identify the jar file that we will add.
Run the command mvn clean install in Maven project. This should build a jar file in the target directory.
Configuring the client with Custom Protocol Mapper
Once the jar file is ready, copy that jar file into the Keycloak configuration. In our case, I am running a Keycloak through a docker container. The docker-compose file Keycloak looks like below:
version: "3.8"
services:
postgres:
image: postgres
volumes:
- postgres_data:/var/lib/postgresql/data
environment:
POSTGRES_DB: keycloak
POSTGRES_USER: keycloak
POSTGRES_PASSWORD: password
networks:
- common-network
keycloak:
image: quay.io/keycloak/keycloak:21.0.0
ports:
- "8180:8080"
command:
- start-dev
environment:
DB_VENDOR: POSTGRES
DB_ADDR: postgres
DB_DATABASE: keycloak
DB_USER: keycloak
DB_PASSWORD: password
DB_SCHEMA: public
KEYCLOAK_ADMIN: admin
KEYCLOAK_ADMIN_PASSWORD: password
volumes:
- "./providers:/opt/keycloak/providers"
- "./themes:/opt/keycloak/themes"
depends_on:
- postgres
networks:
- common-network
networks:
common-network:
driver: bridge
volumes:
db-data:
driver: local
postgres_data:
driver: local
Make sure you have providers directory in your root directory where this docker-compose.yml file is.
Copy the Custom protocol mapper jar file in providers directory.
Start the docker container with docker-compose -f docker-compose.yml up command.
Now let’s configure our client in Keycloak with custom protocol mapper. Once you login to Keycloak admin console, you should be able to see oidc-customprotocolmapper in provider info.
- Now, go to the client and
client-scopes tab.
- Select
client-demo-app-dedicated client scope.
- On the Mappers tab, select
Add Mapper - By Configuration
- Choose Custom Claim Mapper and it will add to your mapper.
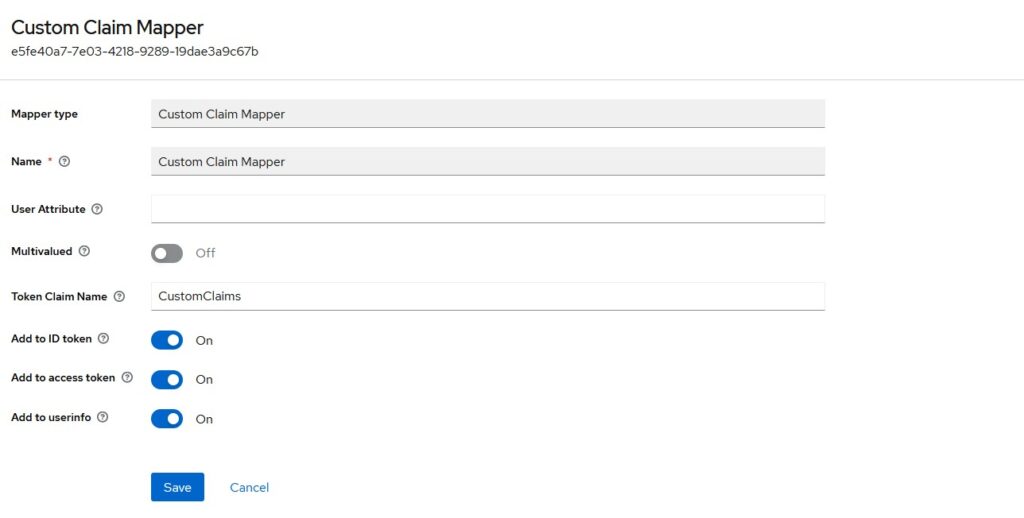
You can choose if you want to include this claim in Access Token or Id Token or Both. Click on Save and it will be added to our list of claims. Now, we are ready to test this mapper.
Demo for Custom Attributes
To test this claim mapper, I will use a postman to call the token endpoint of Keycloak configuration. You will see the access token and id token in response.
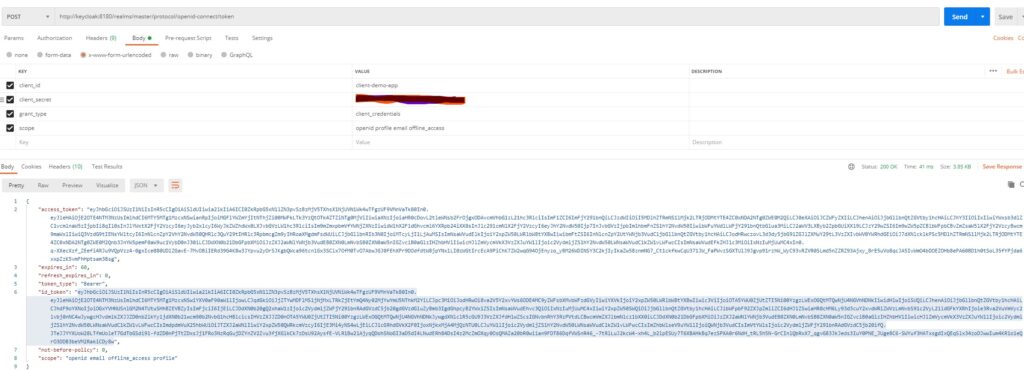
Now if we decode that id token, it will show our custom claim as below:
{
"exp": 1691853775,
"iat": 1691853715,
"auth_time": 0,
"jti": "ce6001e1-c631-4df1-bd87-6260be958d3f",
"iss": "http://keycloak:8180/realms/master",
"aud": "client-demo-app",
"sub": "909ae4f5-e296-4c83-a18d-1406584ea43d",
"typ": "ID",
"azp": "client-demo-app",
"at_hash": "8lXTsTJyF3cxMKnHxAdEAg",
"acr": "1",
"clientHost": "172.25.0.1",
"clientId": "client-demo-app",
"CustomClaims": "SimpleTextAttributeValue",
"preferred_username": "service-account-client-demo-app",
"given_name": "Service",
"family_name": "Account",
"email": "serviceaccount@test.com"
}
You can see the new claim CustomClaims with the attribute value that we had determined in our code.
Conclusion
In this post, we showed how to configure a custom protocol mapper with Keycloak. Keycloak is an open-source IAM tool and it provides capabilities to configure providers and themes.
 And this way, the user was able to log in successfully.
And this way, the user was able to log in successfully.